
Vapi raises $50M Series B
Read More →Vapi raises $50M Series B
Read More →
The Vapi homepage runs 15 voice agents covering 3 use cases across 5 languages. To build these, we did not hand-build them one by one in the dashboard. We started from a rough draft to scaffolding our entire fleet of agents before fine-tuning the results. This post gives you the framework we use to build faster, production-ready agents.
For the Vapi homepage, we needed the same set of scenarios across multiple languages, which means that every time the script changes, every variant needs to change with it. Hand editing all of these introduces human error, drift, and is time consuming. Bootstrapping a fleet of agents in code allows you to move fast and iterate effectively.
To solve this, we generate the agents.
Note: Just want to run the homepage agents as is? Clone the repo, add your
VAPI_PRIVATE_KEY, thenbun run bootstrap. That repo is the hardened end state of the framework below.
There are four phases: plan, draft, bootstrap, harden.
Planning is a cross-functional activity. For the homepage, this was a collaboration with marketing, product, sales, and leadership, resulting in three scenarios: appointment-scheduling, qualification-screening, customer-support, and five languages: en, es, it, fr, and a multi variant that handles 60+ languages in one call. Consider who your experts are in what the final agents should feel like and be able to do. The output of this phase will feed the draft and should cover what scenarios, languages, and details about the voice agent itself.
The single source of truth is one file, ROUGH_DRAFT.md. This is the source of truth that the fleet of agents will be generated from.
Structure:
scenario_name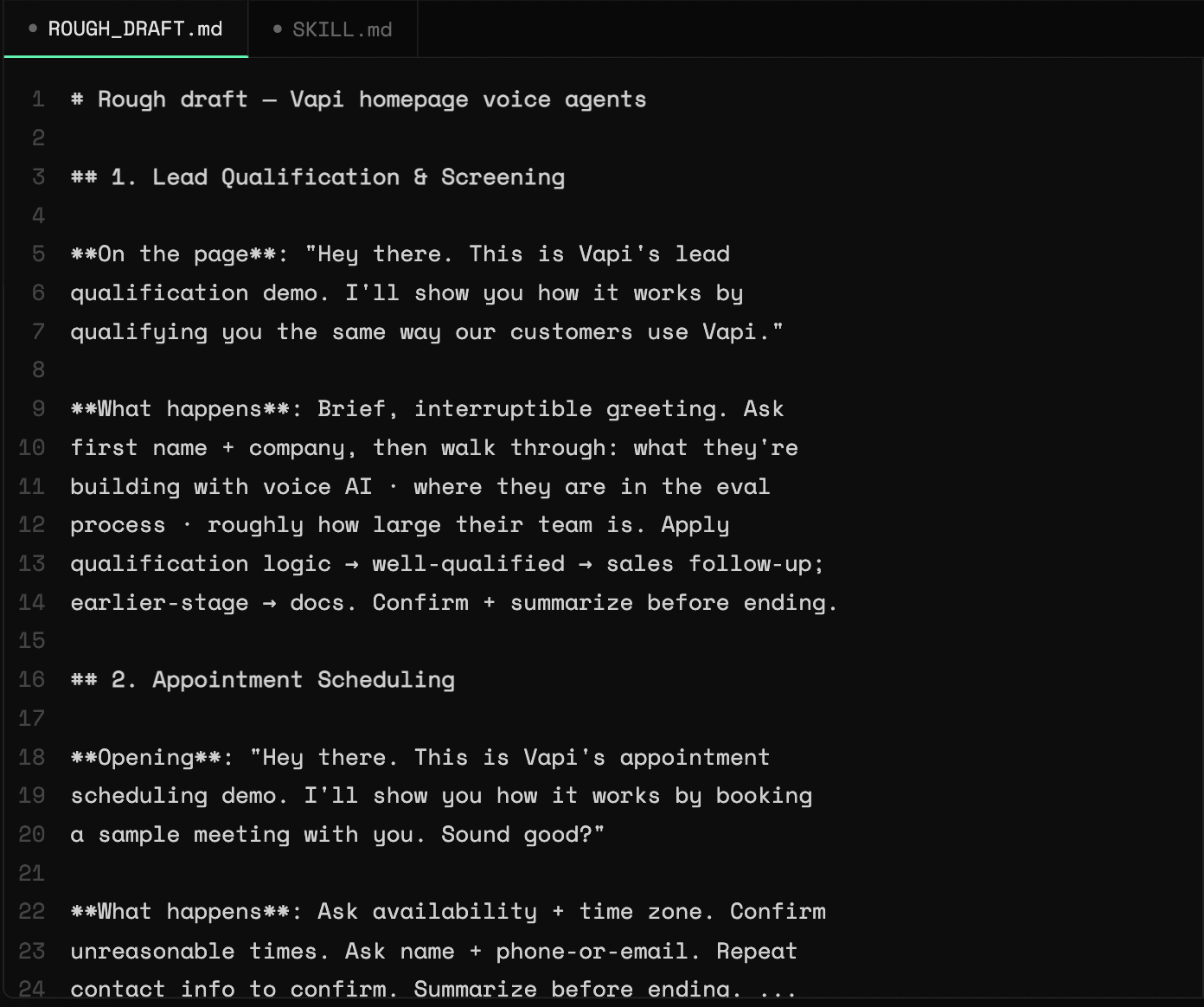
The structure of this draft is important, as it will map deterministically to the configuration:
scenarioId, which becomes the env var that holds the assistant idfirstMessageNote: In our homepage agents, we later refined the ID to append
_IDas a suffix. The conventions you choose are up to you.
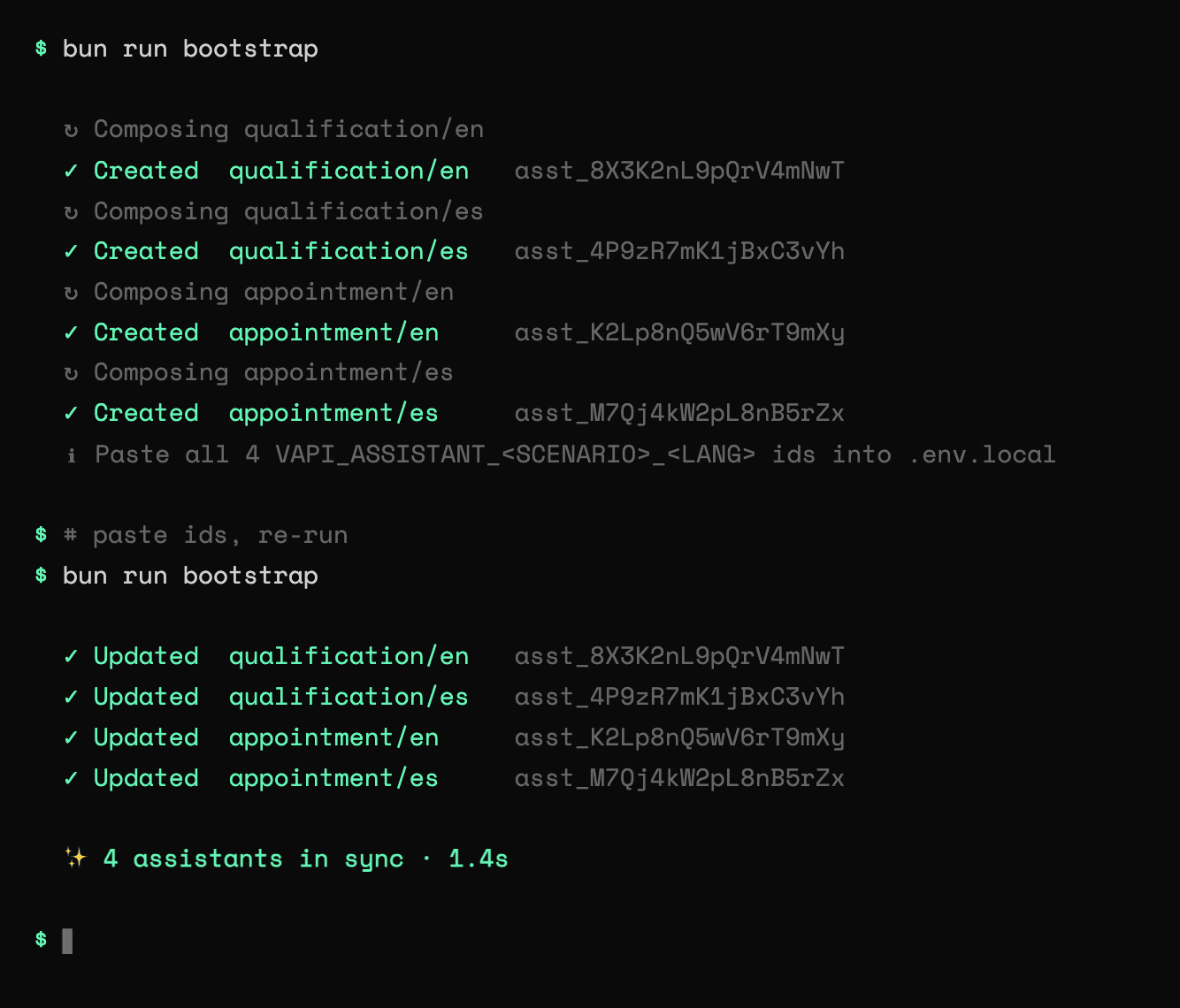
Use the skill pointing at the ROUGH_DRAFT.md, and it will scaffold the whole project, including a small TypeScript spine, which is a per-language voice/transcriber stack, a prompt composer, a scenario registry, an assistant builder, and the bootstrap entry point. Run bun run bootstrap to generate your agent fleet.
What the skill ships as defaults:
en + es. Adding a third is one entry in each language record.gpt-4.1 at a flat temperature of 0.5, set once in buildAssistant.ts.eleven_turbo_v2 (EN) / eleven_multilingual_v2 (ES).nova-3 (EN) / Soniox stt-rt-v4 (ES).loadPrompt composition: one body.md per scenario drives every language. EN returns the body unchanged; ES prepends a Spanish preamble with the scenario's localized off-topic redirects spliced in. One wording change to body.md re-applies to all variants.assistants.update(id, body); not set runs assistants.create(body) and prints the new id. State lives in .env.local, so reruns are safe, and a stale id (deleted assistant, or a different org after a key rotation) falls back to create on a 404..env.local; the second run finds them and updates in place instead of duplicating.
The skill stops here, as the generated body.md is persona driven and handled in the next phase.Bootstrapping speeds up development, but the agents are still rough. This phase is the human-in-the-loop phase to refine your agents for production. Here you can:
en + es to five languages.multi fallback plan (OpenAI tts-1, then Cartesia sonic-3). The EN transcriber was swapped from nova-3 to Deepgram flux-general-en with tuned end-of-turn thresholds; non-EN kept Soniox with a Deepgram nova-3 fallback. A brand-vocabulary list keeps product names from being misheard.body.md files grew hard-constraint, identity/security, and "hard off-topic / chaos handling" sections, plus localized off-topic-<lang>.md redirect lines. This is where guardrails and off-ramps get added. Natural variation comes from the prompt itself via disfluency vocabulary, laughter rules, and banter sections.analysisPlan with a summaryPlan (always summarize in English, whatever language the call was in) and a structuredDataPlan that extracts a typed JSON record. For example, qualification's follow_up_intent_score on a 0 to 10 rubric, plus name, company, and use case.cs_idle_topic_suggest) that fires on customer.speech.timeout after about 12s and speaks a prompt from idle-hook.md.Once your agent fleet is live, this framework allows for fast and effective iteration. To make changes, edit the source manually or prompt what changes you want in your favorite coding agent pointed to your repo, then re-run bun run bootstrap. This runs an upsert based on the stored assistant ids, so it will not duplicate your agents. A deleted or stale id will fall back to a fresh create.
Example updates:
body.md once and this reapplies to all agents.languages.ts.voiceOverride on the scenario.You can also grow the scenarios if you have a new use case after you go live.
body.md, a scenarios/<id>.ts, and register it in the scenario registry and id types.languages.ts, and a shared language section or preamble.
The important thing to remember is to keep the bootstrap as the source of truth. If you make an edit in the dashboard, the next run will overwrite the edits.










































































