
Vapi raises $50M Series B
Read More →How we solved latency at Vapi

Latency is the enemy of conversational flow.
In real-time voice applications, the most important metric is latency to response, measured as the duration between a user’s end of statement and the agent’s start of statement. This cycle is called turn-taking.
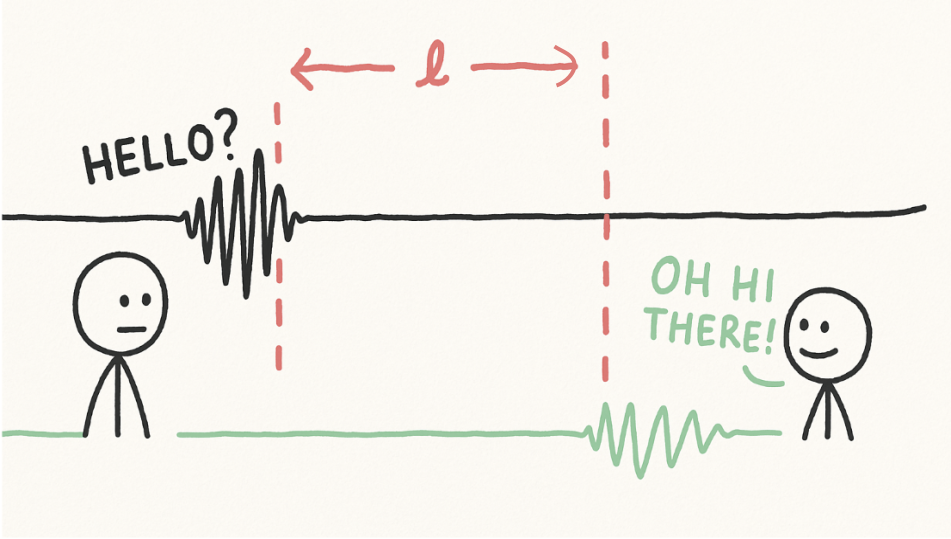
Conversational flow breaks when latency exceeds 1200ms. That’s the rough time it takes for the user to have a tangential thought.
This gives us a strict 1200ms latency budget for every turn in a conversation.
We treat this budget like a scarce resource. If we can save milliseconds in the LLM reasoning step, we can spend them on a higher-fidelity TTS model for a more human-like voice.
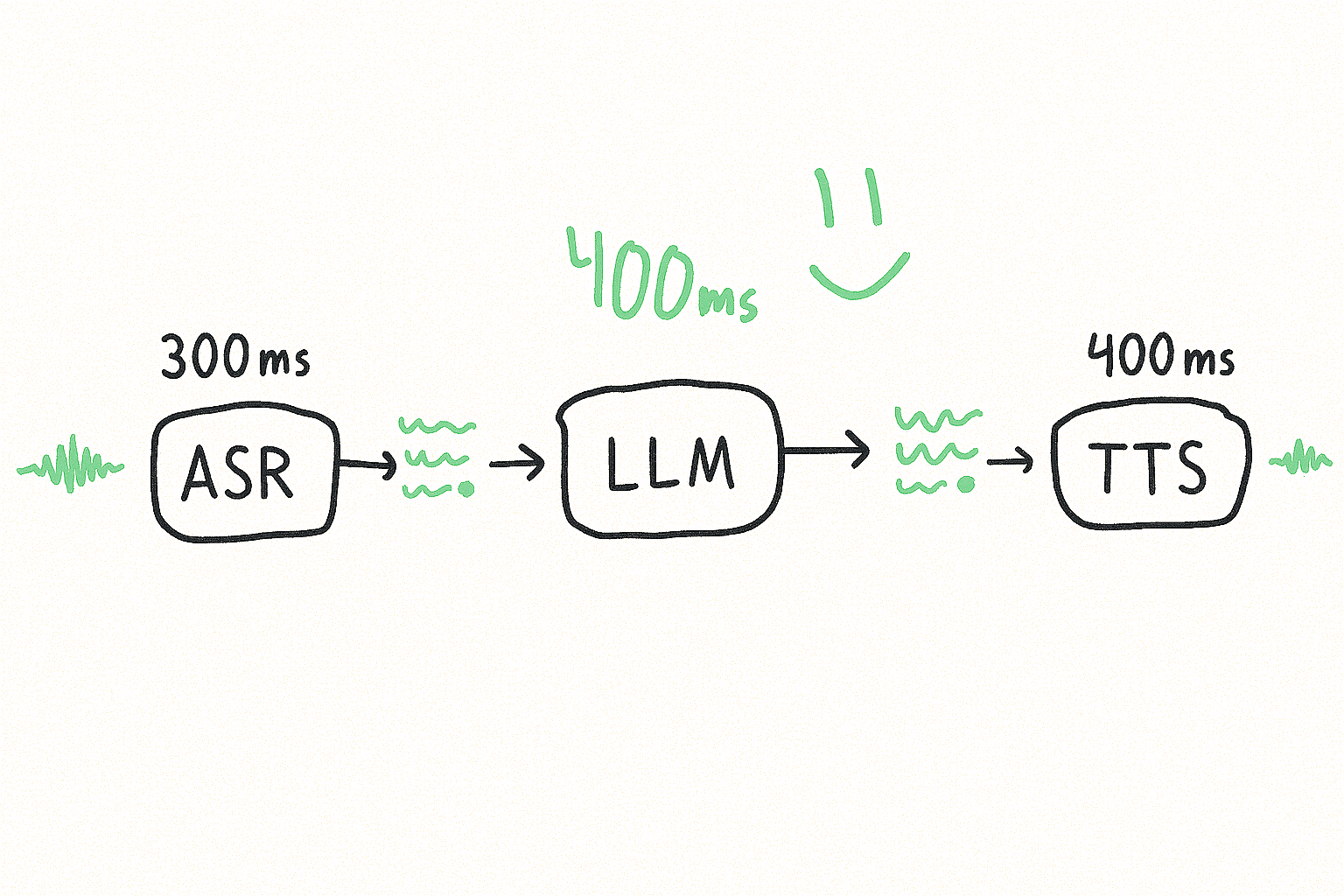
Here’s how that 1200ms budget is typically spent in a speech-to-speech pipeline:
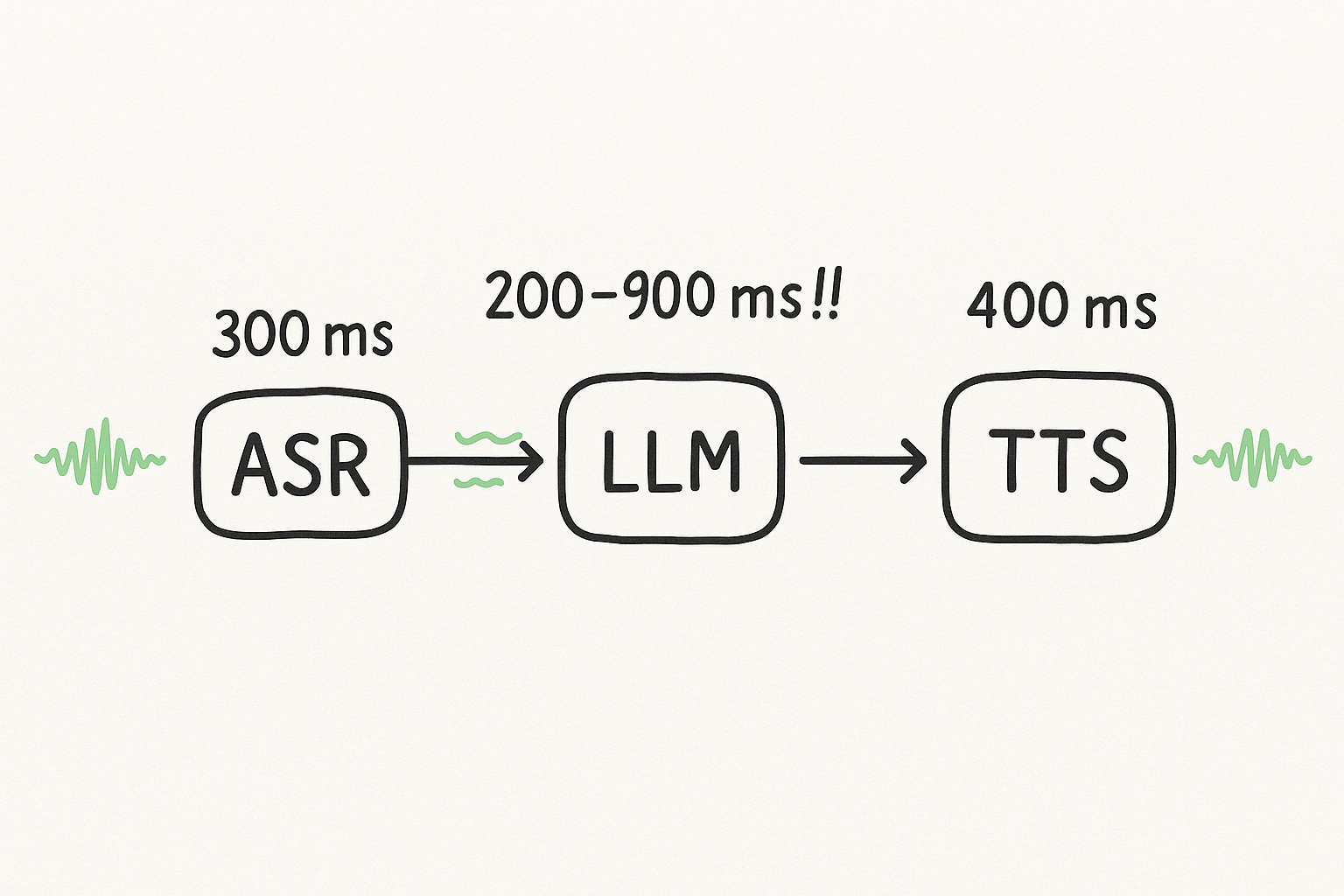
The ASR (speech-to-text) and TTS (text-to-speech) models are fairly optimized by their underlying providers.
The bottleneck is almost always the LLM.. specifically, the time to first meaningful sentence.
LLM providers advertise impressive speeds, but their benchmarks rarely hold up in production.
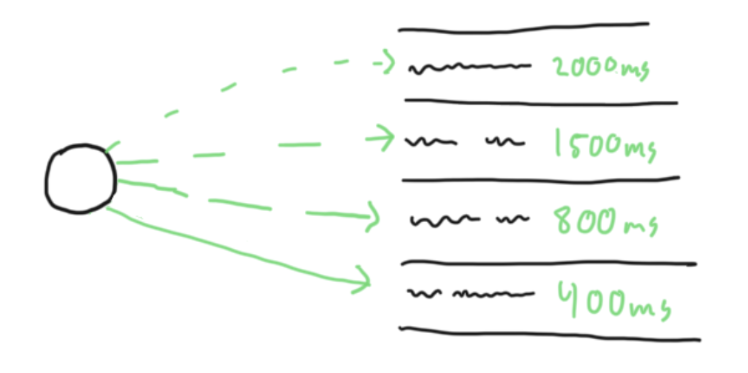
We tracked OpenAI’s GPT-4o mini over a 7-day period. The latency was anything but stable:
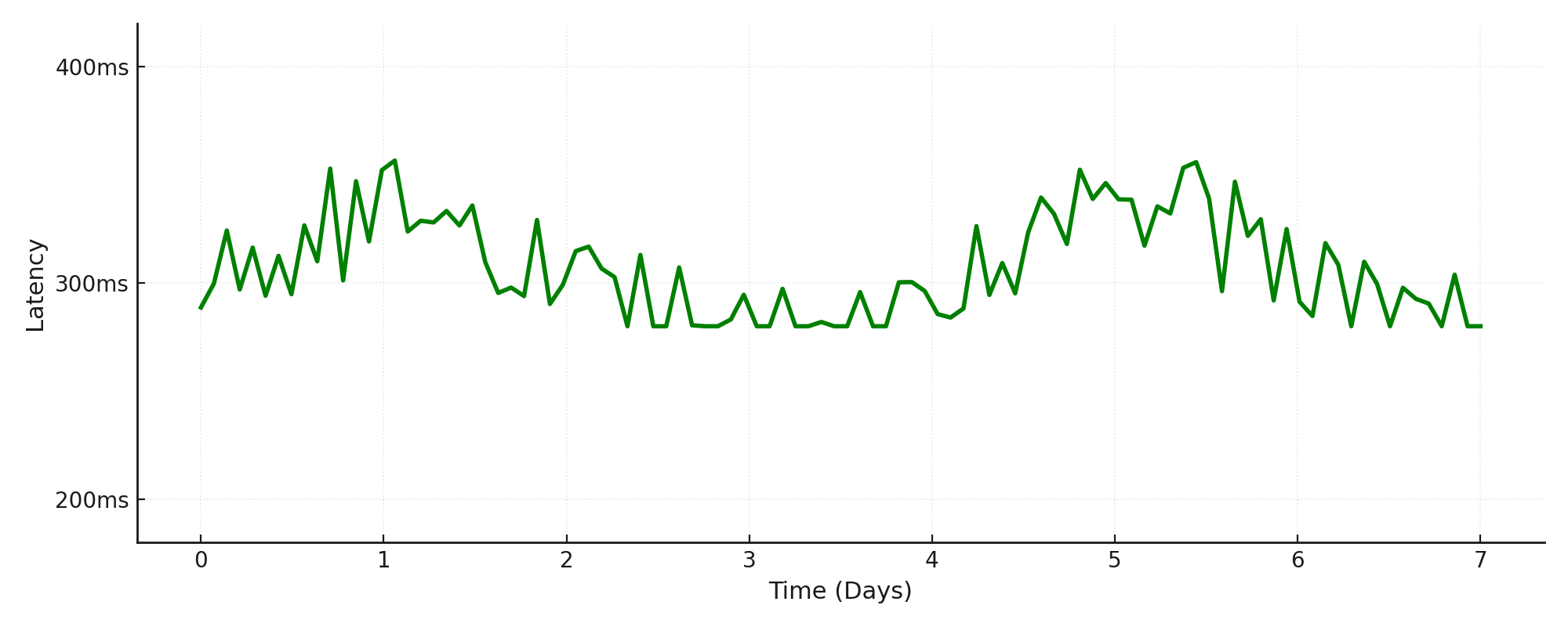
A model that performs well on a Friday night can be unusable on Monday morning. This volatility is the real enemy of conversational AI.
We observed the same pattern across all available regions in Azure OpenAI; they all vary independently.
We needed a system that dynamically routes every request to the absolute fastest deployment available at that exact moment.
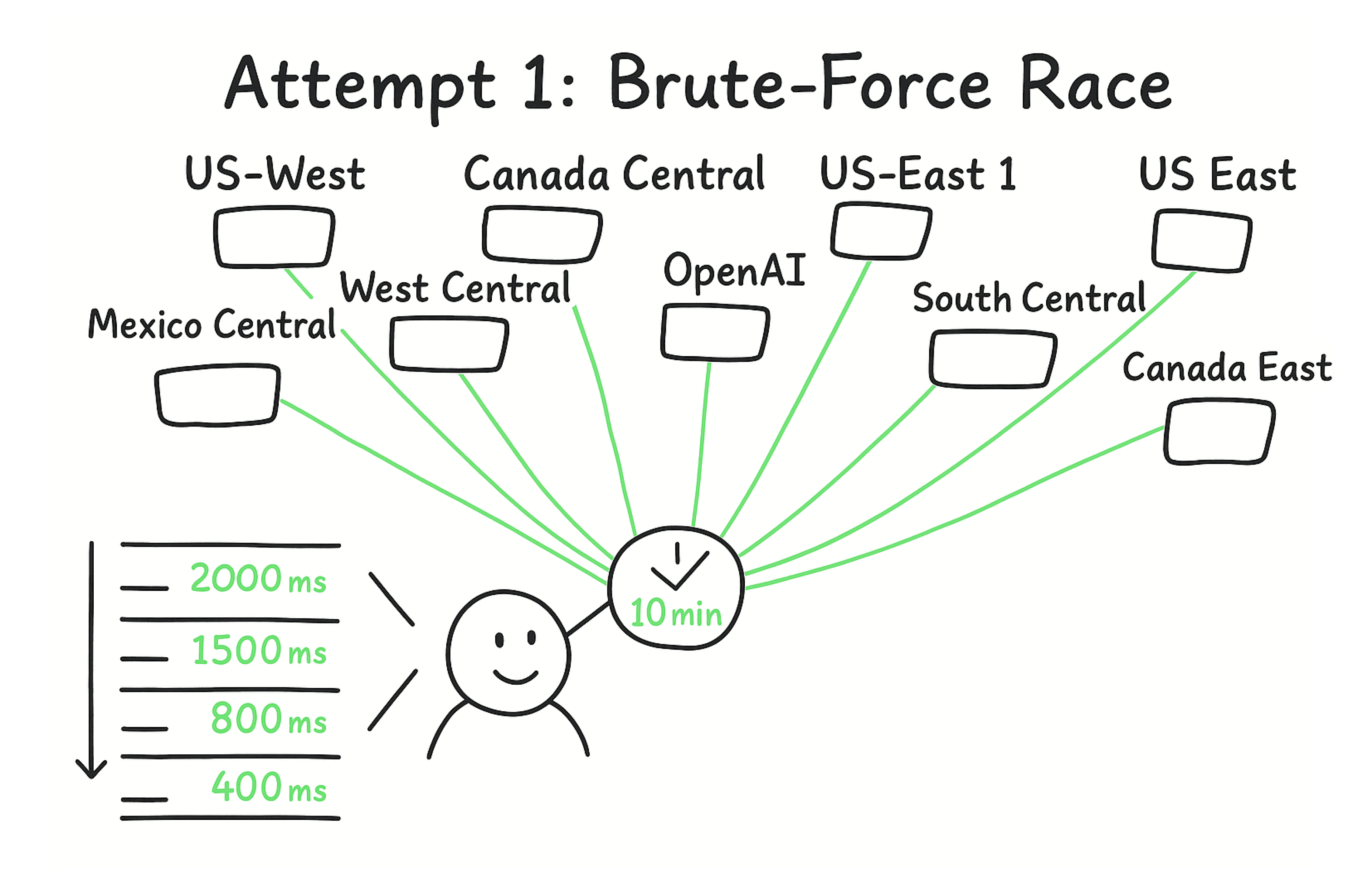
Attempt 1: The Brute-Force Race
The obvious solution is to send every request to all 40+ Azure OpenAI deployments and use the first one to respond. This is bruteforce optimal for latency, but it costs 40x the tokens. Unacceptable.
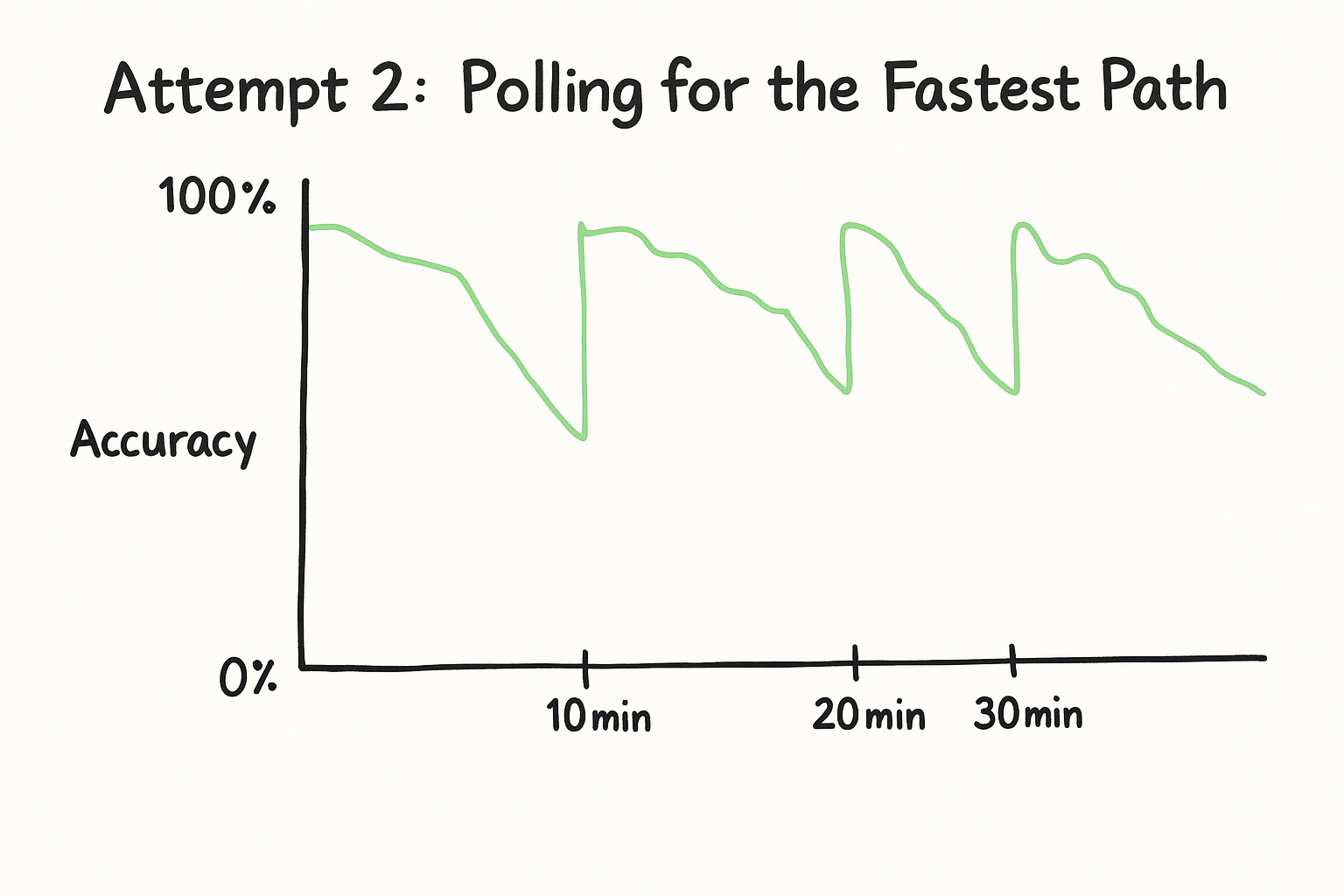
Attempt 2: Polling for the Fastest Path
We realized we could gauge relative latency by polling each deployment with a cheap, single-token request. This is O1 cost, great!
We built a system to poll every 10 minutes, costing about $400/day.
The results are stored in Redis. When a call comes in, we check Redis, pick the fastest deployment, and route the request.
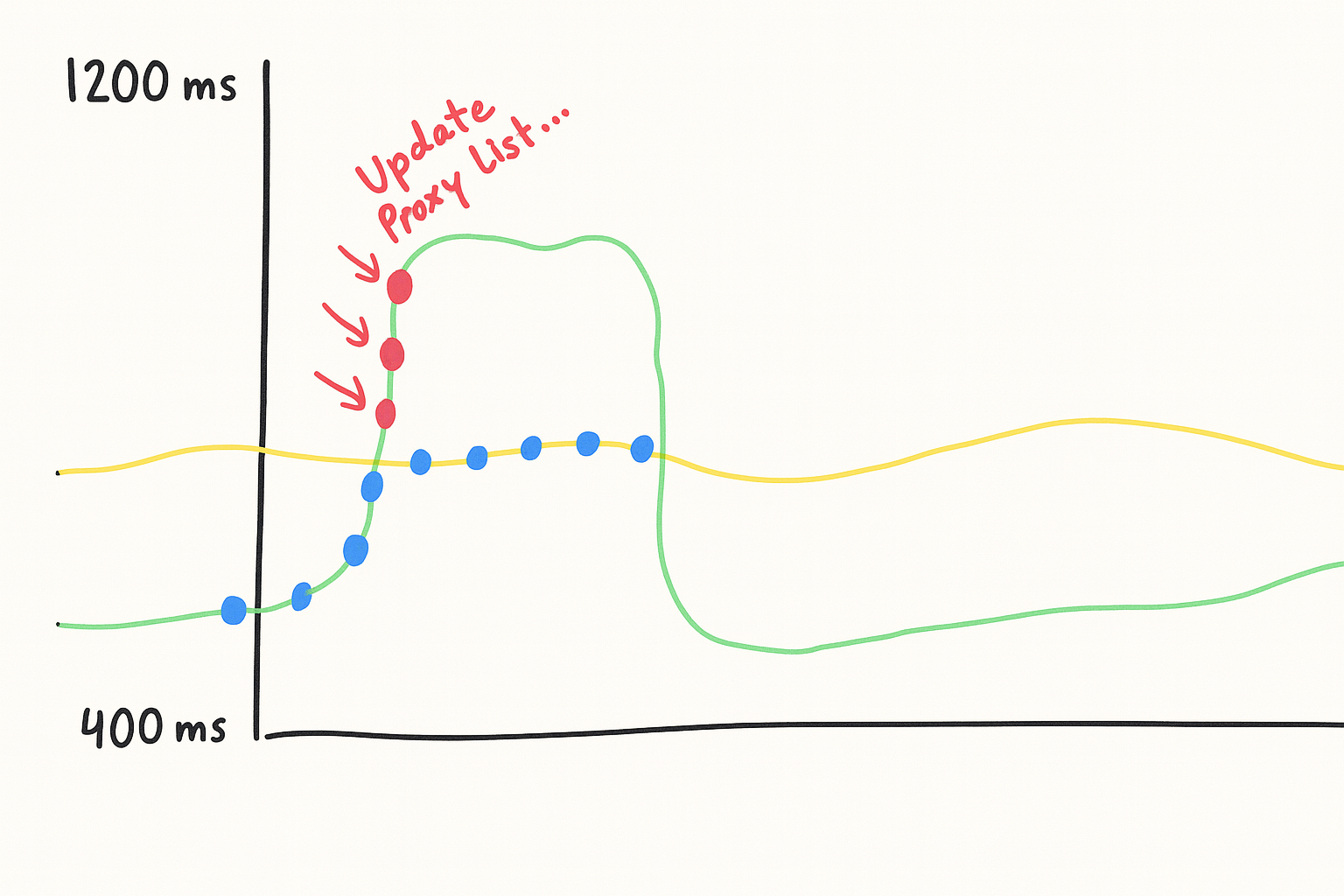
This improved average latency, but we still saw spikes lasting 5+ minutes.
When a deployment degraded between polls, we were stuck routing traffic to a slow endpoint for the next 10 minutes. The accuracy of our proxy list would look like this:
Attempt 3: Using Live Data + Exploration
We needed fresher data.
By using the latency from our live production requests, we could update our proxy list in real-time.
If our fastest deployment spiked, we’d detect it on the next request and immediately rotate it out.
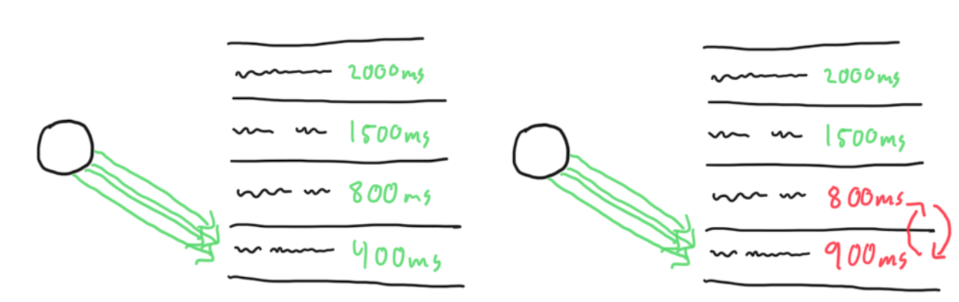
This solved the stale data problem, but created a new one: we were only exploiting our known winners.
We were no longer exploring the other 39 deployments between polls. What if one of them had become faster? We would never know.
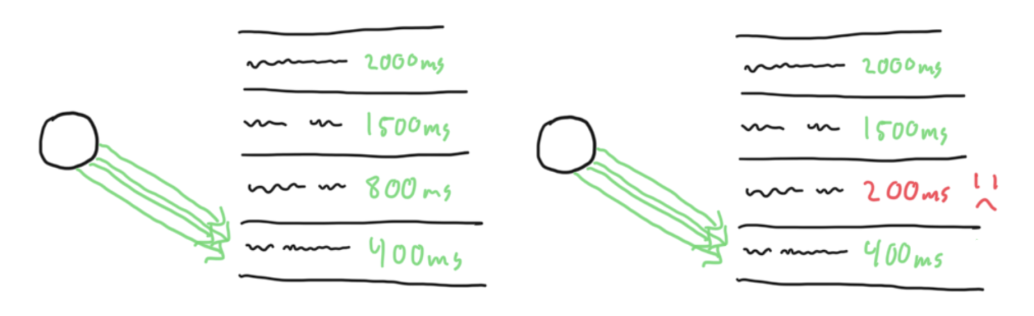
The solution was to segment our traffic. We route the vast majority of requests to the current fastest endpoint (exploitation), but send a small, statistically significant subset to test the others (exploration).
We had a system that could intelligently route requests to the fastest deployment.
We thought we'd solved it. But alas, we were wrong.
The Real Problem
We were still seeing about 5% of conversation turns hang for up to 5000ms.
Which is the absolute death spiral of conversation flow:
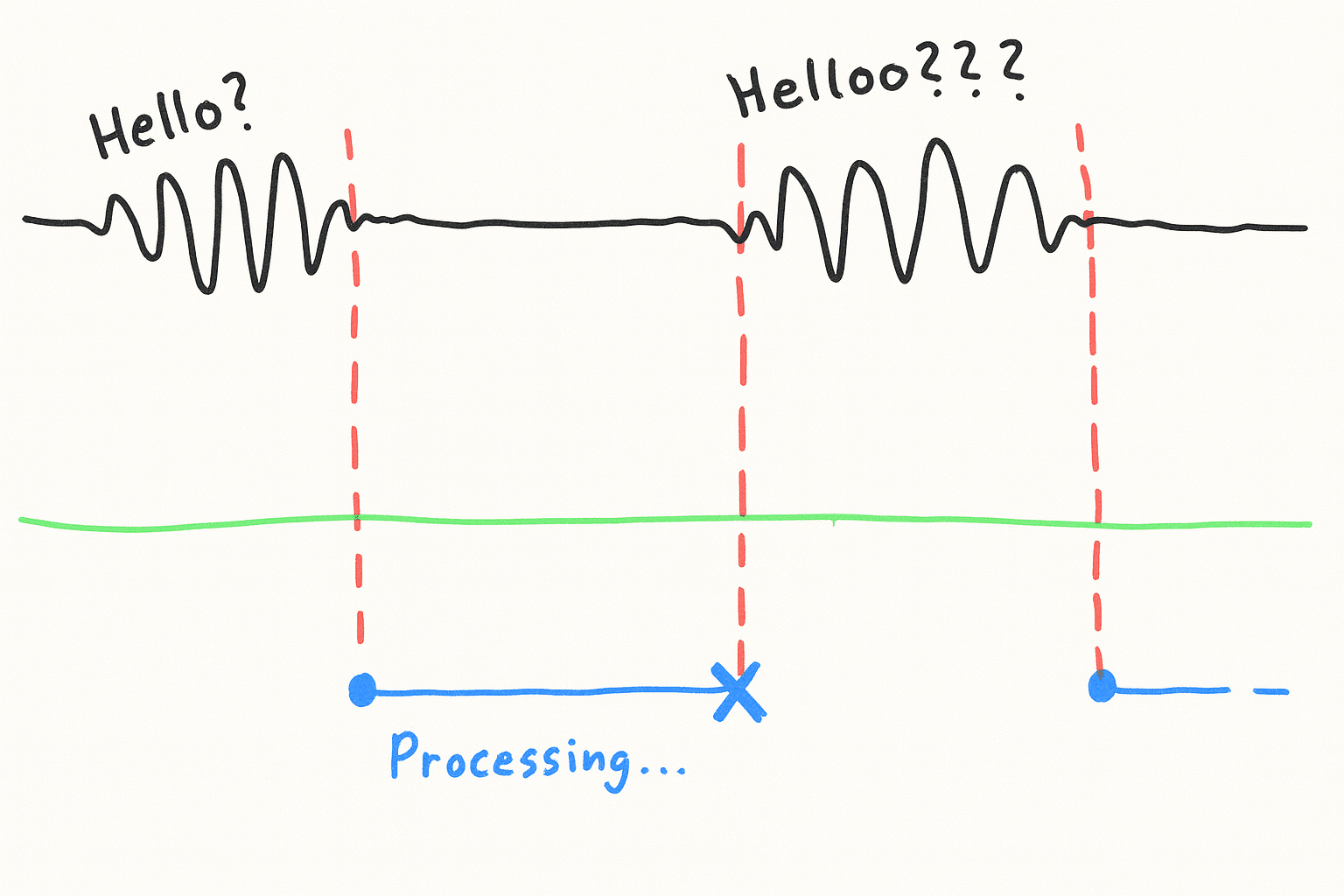
After digging in, we found the cause: sometimes, a request to a provider like Azure OpenAI just hangs. No error, no timeout, nothing.
The first request to hit the hang gets shot. Our system would detect it and route subsequent traffic away, but that first user's experience was already ruined:
The final piece of the puzzle was building a recovery mechanism. If a request to the fastest deployment takes too long, we don't wait. We cancel it and immediately fire off a new request to the second-fastest deployment.
Setting this threshold is tricky. Too aggressive, and you incur extra costs from unnecessary fallbacks. Too slow, and the user is left waiting.
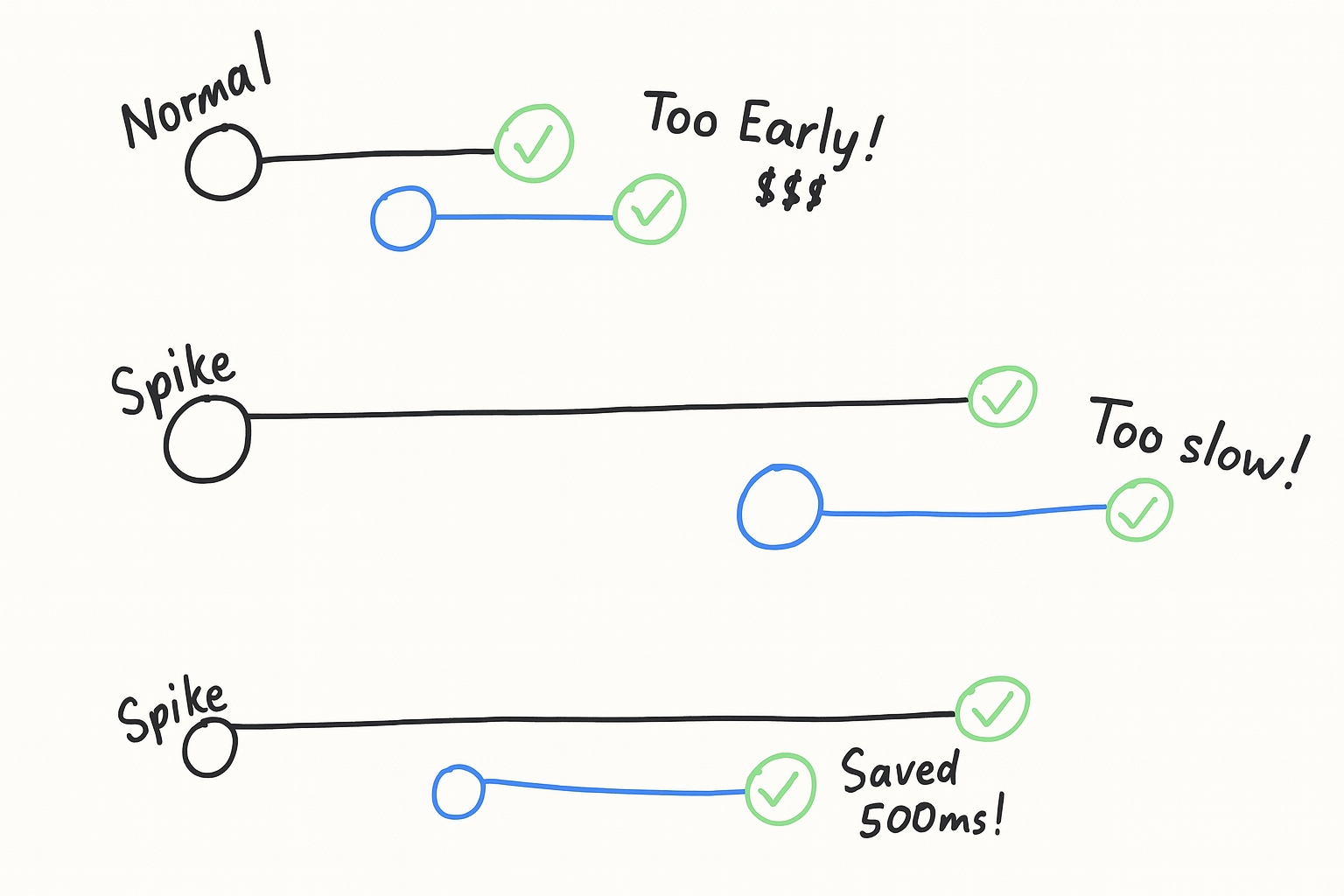
But, each deployment has its own unique performance profile, so a single threshold wouldn’t do the trick.
We calculated the historical standard deviation for each individual deployment and set a dynamic threshold based on what constitutes abnormal latency for that specific deployment.
If the first request is an outlier, we fall back to the second.
If the second is an outlier, we fall back to the third. And so on.
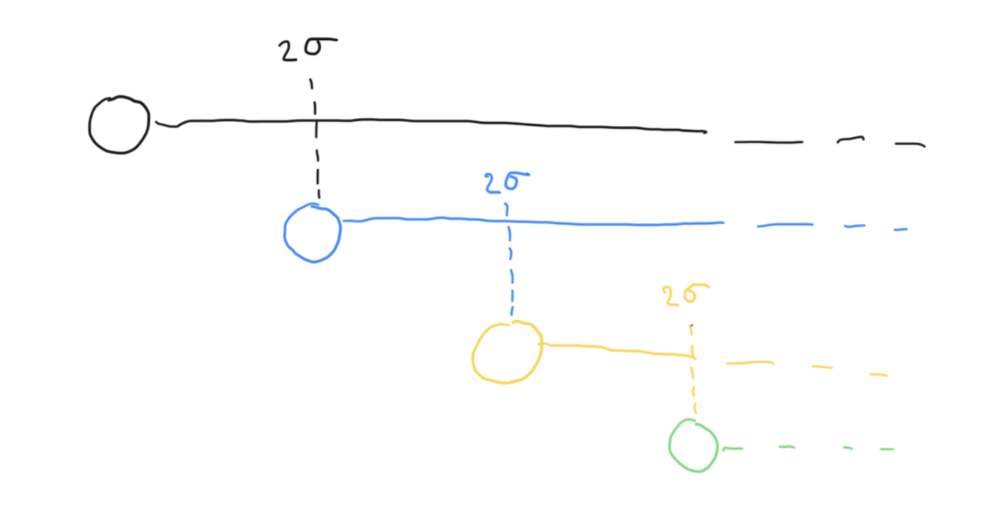
This is what it takes to make an off the shelf model like GPT-4o reliably fast for real-time voice.
This system alone shaved over 1000ms off our P95 latency.
It’s one of hundreds of infrastructure problems we've had to solve to wrangle these models into something developers can actually use.











































































