
Vapi raises $50M Series B
Read More →How We Solved DTMF Reliability in Voice AI Systems

Building a voice agent that can navigate a phone menu might seem easy.
You generate a tone, the system hears it, and the call moves forward.
Well, it's not that simple. One of our forward-deployed engineers, Steven, was working with an enterprise customer trying to get their agent deployed.
Their use case involved navigating IVR menus across five different providers, and the unreliability was killing their success rates.
The failing DTMF tones led to longer call durations and frustrated end-users.
After countless hours of debugging failed call flows and frustrated user reports, we mapped out the core issues.
It comes down to 3 things:
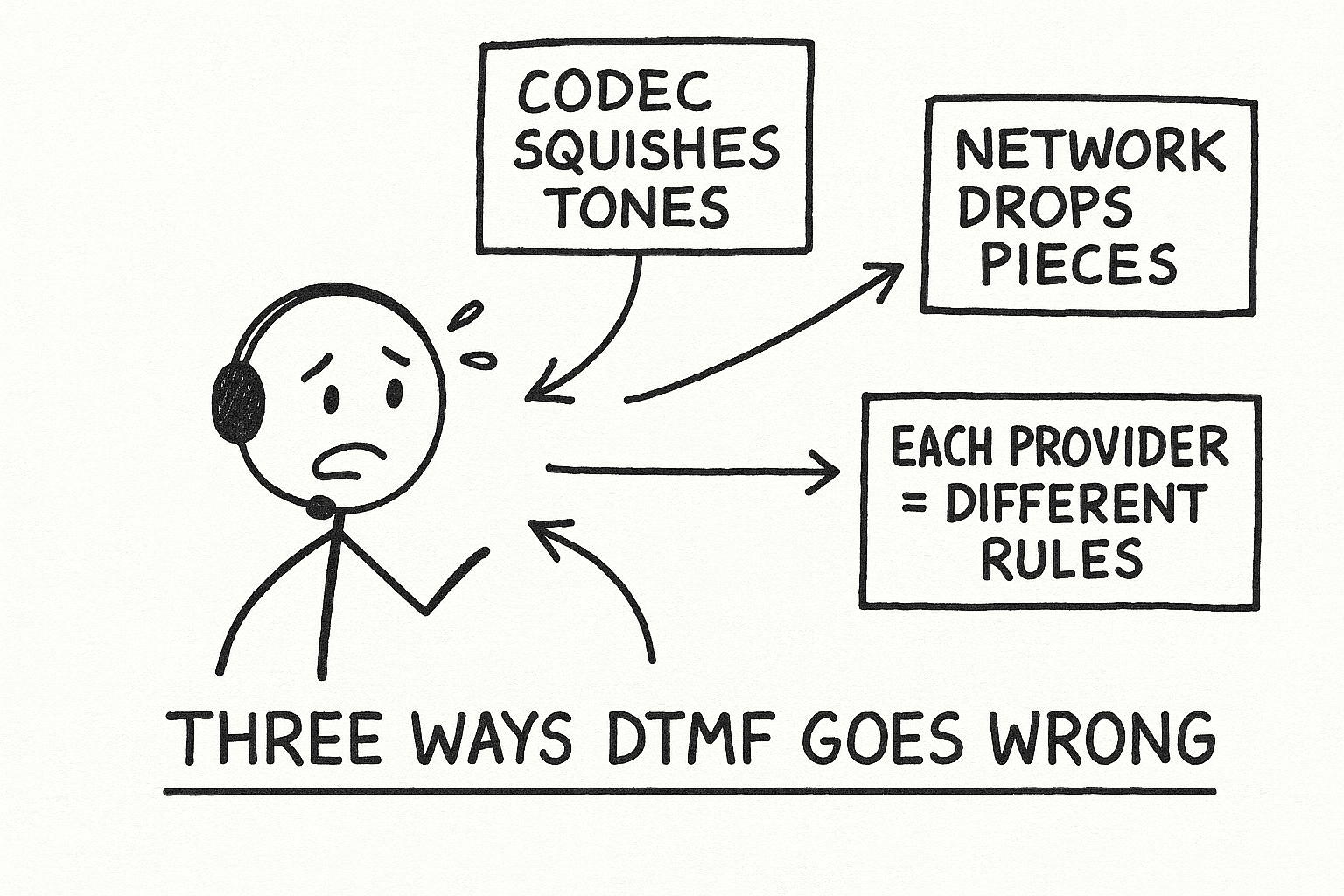
The 3 Ways DTMF Can Go Wrong
Problem #1: Mangled Audio
Voice calls run on codecs like Opus or G.711, which are built to compress human speech. They use psychoacoustic models that prioritize the frequencies in our voice (roughly 300-3400 Hz) and discard what the human ear doesn't perceive as critical.
A DTMF tone however is not speech. It's a precise combination of 2 pure sine waves.
For the digit "1", it's exactly 697 Hz and 1209 Hz. When a codec compresses this signal, it quantizes, filters, and distorts these pure frequencies.
The harmonics shift, the phase relationship breaks. To the receiving system, the tone becomes an unrecognizable smudge of audio. The result is a failed input.
Problem #2: The Network is Unreliable
Voice packets travel over public networks. This means packet loss, jitter, and bandwidth fluctuations are unavoidable.
DTMF detection algorithms, often based on Goertzel or FFT approaches, need a clean, consistent signal for at least 40-50ms to confirm a digit.
Jitter reorders packets, creating gaps in the tone. Packet loss deletes parts of it entirely.
A receiving IVR might hear a garbled signal, nothing at all, or misinterpret a "11" as a "7".
This is especially true for legacy IVR systems that are notoriously unforgiving.
Problem #3: Every Provider is a Special Case
Yes, there's a standard for sending DTMF out-of-band: RFC 2833. It defines sending the DTMF event in a separate RTP payload, bypassing the audio stream entirely.
In a perfect world, everyone would use it, and this blog post wouldn't exist.
The problem is, production isn't perfect. The real world is a patchwork of legacy IVR systems, custom telephony setups, and carrier-specific interpretations.
We found that:
- Many older IVR systems don't support RFC 2833 and only listen for in-band audio tones.
- Among providers that do support the standard, implementation details like timings, payload formats, and acknowledgment mechanisms vary just enough to cause silent failures.
- Other providers use entirely different methods, like SIP INFO messages.
An approach that works perfectly on one provider fails on another. This creates a compatibility matrix from hell for any developer.
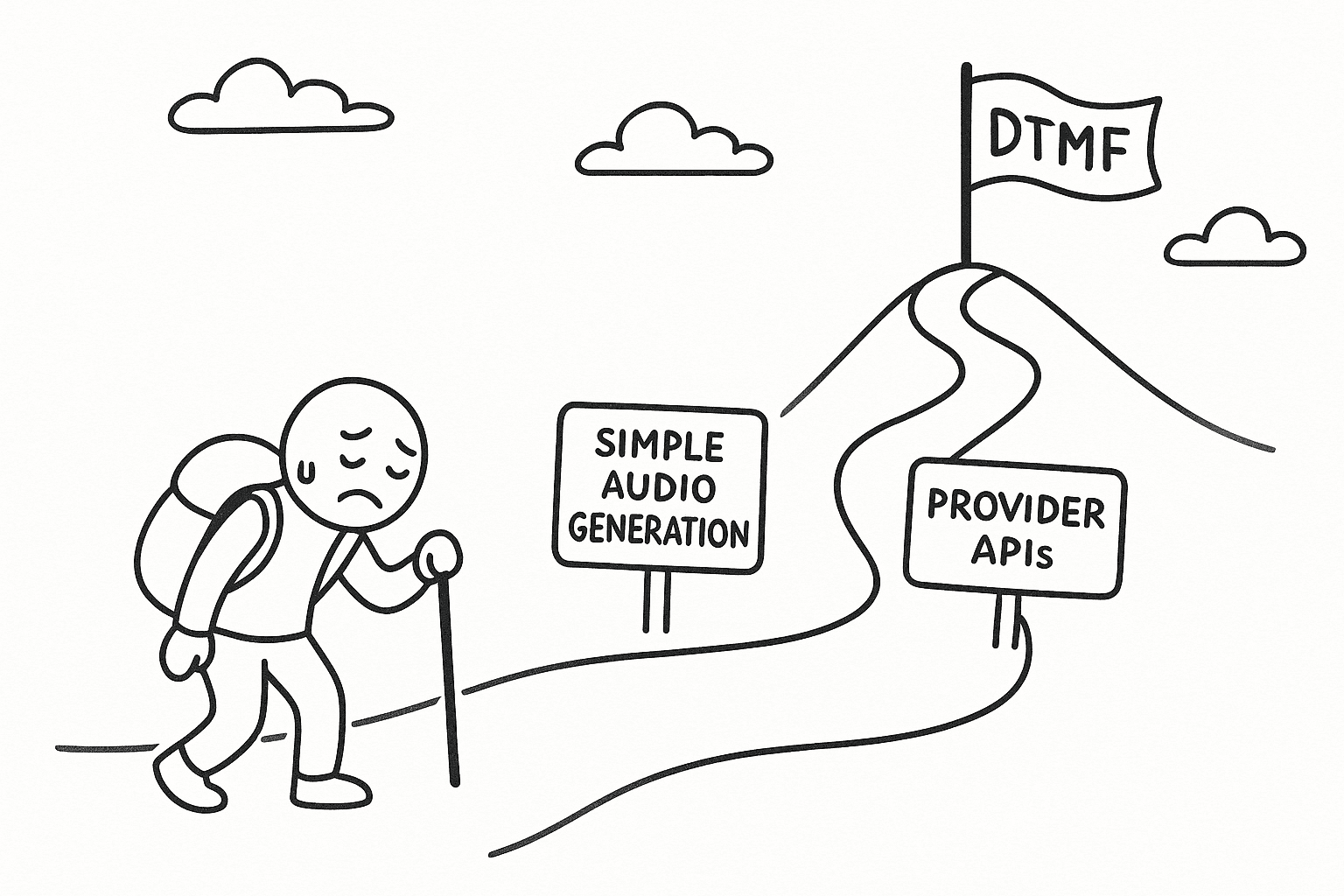
Our Journey to a Solution
The First Attempt: Simple Audio Generation
We started with the obvious approach: generate DTMF tones as audio and send them through the voice stream. We carefully crafted each tone using the exact frequencies:
- "1" = 697 Hz + 1209 Hz
- "2" = 697 Hz + 1336 Hz
- "3" = 697 Hz + 1477 Hz
And so on...
This worked on localhost. It worked in a clean network. But it failed inconsistently in production. The combination of codec mangling and network noise made it too unreliable for real-world use.
The Second Attempt: Use Provider APIs
Next, we used provider-native APIs to send DTMF digits out-of-band.
This bypasses the audio stream entirely, avoiding compression issues.
This was a step forward, but reliability was still inconsistent. Some providers had robust APIs, others were flaky. Some didn't support it at all for certain call types.
We had traded one set of problems for another.
The Only Thing That Worked
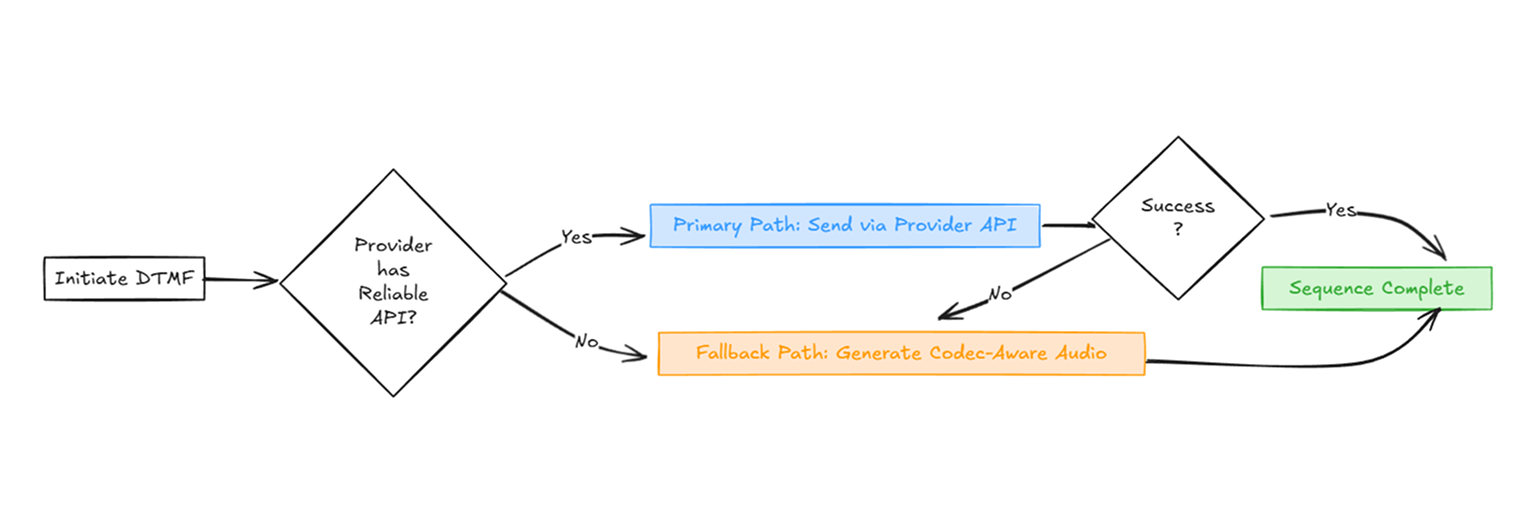
We realized there is no single silver bullet.
The only solution is an intelligent, adaptive system that uses the best tool for the job on a per-call basis.
Here is the architecture we built:
- Primary Path: Provider-Specific DTMF (RFC 2833 / API).
When we’re on a call with a provider that has a reliable out-of-band DTMF API, we use it. This is the cleanest, most direct method. We built provider-specific adapters to handle the quirks of each API. - Fallback Path: Codec-Aware Audio Synthesis.
If the primary path is unavailable or fails, we fall back to generating audio. But we don't just generate a simple tone. Our synthesis engine is codec-aware. It generates tones at 16kHz with specific amplitude normalization designed to survive compression cycles with minimal distortion.
The Results
By abstracting this complexity away, we achieved predictable performance.
- Provider API Method: >90% success rate.
- Audio Fallback Method: >80% success rate.
- Combined Hybrid System: >93% overall success rate.
Users no longer get stuck in IVR loops. Our support queue for DTMF-related issues is nearly empty because the system now self-heals.
DTMF is a perfect example of a problem that looks simple on the surface but hides immense technical depth. The "right" architecture isn't the most elegant one on a whiteboard but one that is a resilient, multi-layered system that works in the messy reality of production.
We're now applying this hybrid, adaptive model to other hard problems like voicemail detection and call transfers.











































































