
Vapi raises $50M Series B
Read More →How We Built Vapi's Voice AI Pipeline: Part 2

In Part 1, we explained why a streaming architecture is the only way to build a conversational agent that doesn’t feel robotic.
The concept sounds straightforward: process audio continuously instead of waiting for complete chunks. But the real world is a chaotic mess of background noise, unpredictable pauses, and bad cell service.
In this part, we will cover how we built the components that tame that chaos before it ever reaches the LLM.
Problem #1: Voice Activity Detection
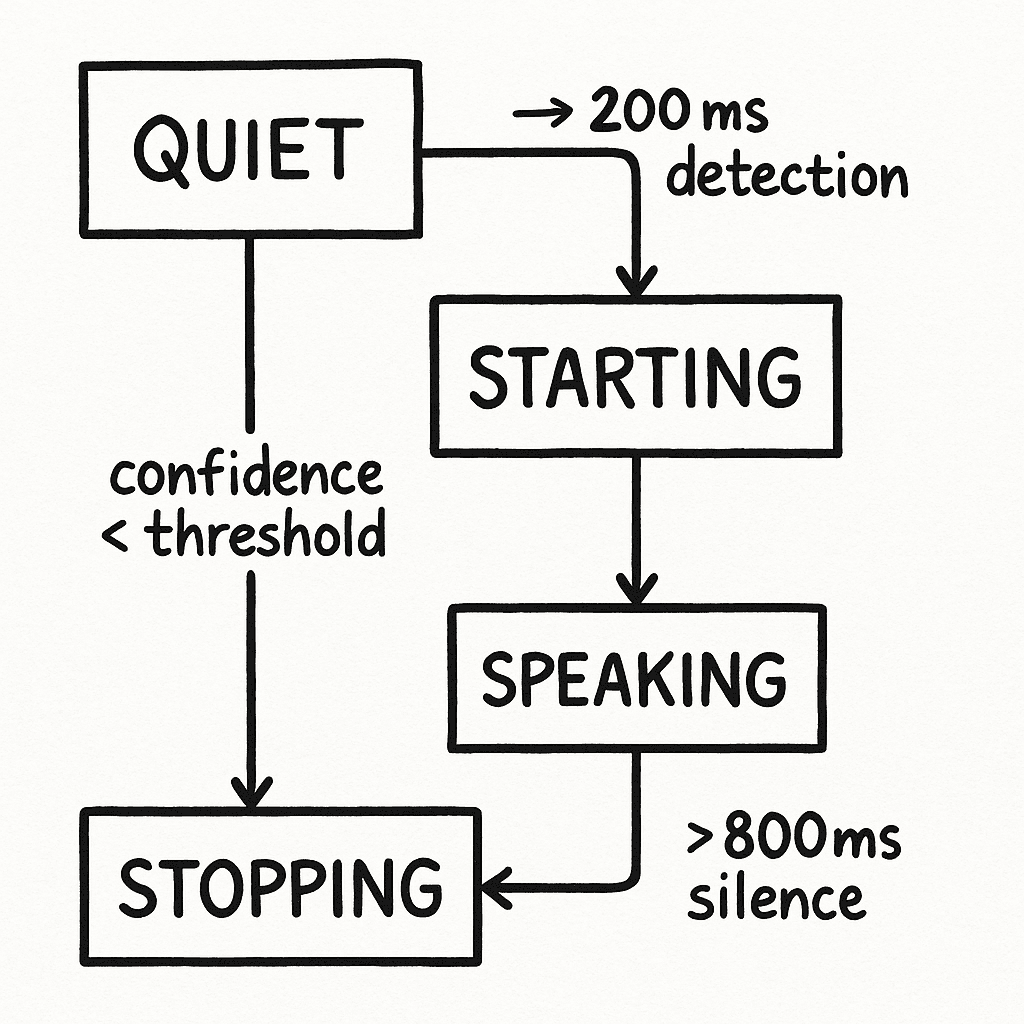
The first component in the stream, Voice Activity Detection (VAD), has one job: to detect when someone is speaking. A simple volume threshold is the obvious approach, but it’s also wrong. A simple VAD system can't distinguish between the person you want to hear and audio you want to ignore.
Our VAD is built around a state machine with four distinct states and different thresholds based on a confidence score for starting versus stopping speech to prevent nervous switching:
- QUIET: No meaningful audio detected (confidence score below threshold).
- STARTING: Speech beginning detected, waiting for confirmation (requires ~200ms of sustained detection).
- SPEAKING: Active speech confirmed (confidence above the threshold for a sufficient duration).
- STOPPING: Speech ending detected, waiting for confirmation (requires ~800ms of sustained silence).
This creates a rolling average that responds quickly to changes while filtering out noise.
Even this isn’t enough. Every person speaks differently. Our system maintains a 30-second rolling window of audio levels and uses the 85th percentile as a dynamic baseline, automatically adjusting to quiet speakers, loud speakers, and noisy environments.
To ensure reliability, we run the VAD system in a separate process. Audio flows between processes through stdin/stdout pipes, with probability scores returned as ASCII strings. When the process fails, the system automatically respawns it without dropping the conversation.
Problem #2: Audio Preprocessing

Phone calls are inherently messy. Most voice AI systems assume clean audio. We have to handle the chaos. Our biggest challenge is background speech. Standard denoisers preserve human speech—including speech you don't want, like TV audio playing in the background.
So we built an adaptive thresholding system that learns the difference between speakers in real-time:
- Baseline Tracking: Monitors RMS amplitude over 3-second rolling windows using 20ms audio chunks.
- Dynamic Thresholds: Uses the 85th percentile of the audio level distribution as the filtering threshold.
- Continuous Adaptation: Updates the baseline every 100ms using exponential smoothing.
- Media Detection: Automatically switches to more aggressive filtering when consistent background audio is detected.
One core insight that we learned from this is that background speech is typically quieter than the primary speaker.
We add a 500ms grace period to avoid cutting off the start of words and implement automatic switching between normal and media-optimized filtering modes. The system maintains several adaptive parameters, including static fallback thresholds around -35dB and baseline offsets that automatically adjust when TV or music is detected in the environment.
Problem #3: Streaming Speech Recognition
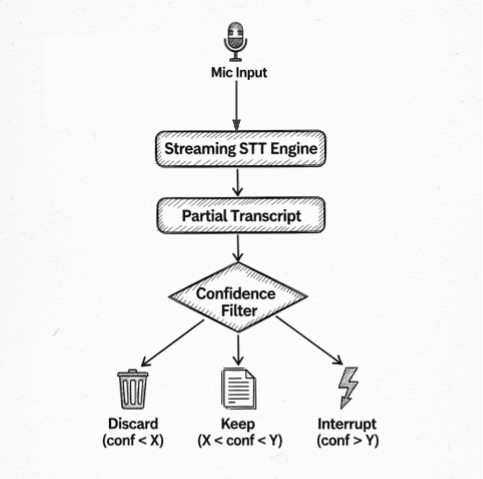
Streaming Speech-to-Text (STT) is great for latency, but it forces you to make decisions with incomplete information. When is a partial transcript confident enough to act on?
We use confidence-based filtering with multiple decision points:
- Basic Filtering: Very low-confidence transcripts are discarded automatically.
- Interruption Decisions: Only higher-confidence transcripts can interrupt the AI while it's speaking.
- Edge Case Handling: Single-letter artifacts and common false positives are filtered out.
This prevents the agent from making premature responses to low-confidence partial transcripts. We also support multiple STT providers with automatic fallback if the primary provider fails. The system handles provider-specific quirks and optimizes for each provider's strengths while maintaining consistent behavior across different STT engines.
Problem #4: Endpointing
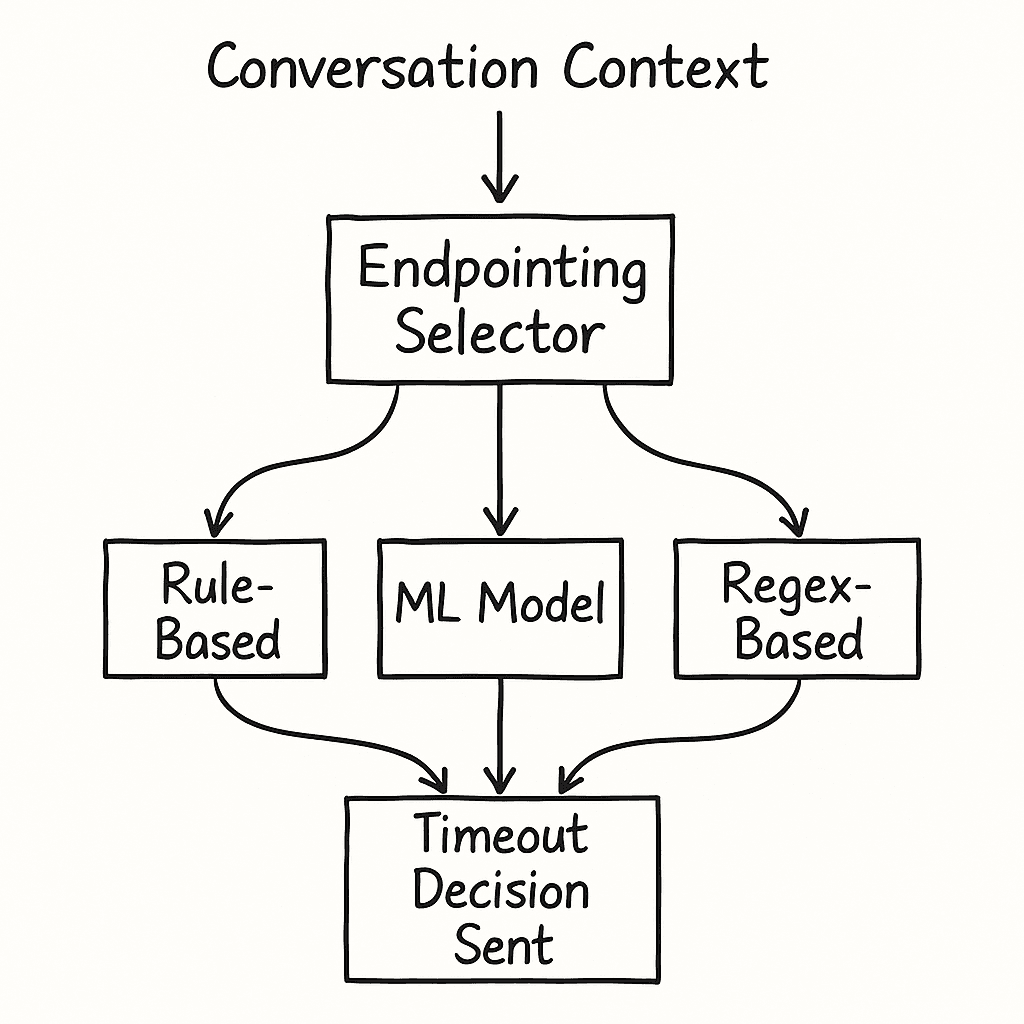
Determining when someone has finished speaking is the most underestimated challenge in voice AI. A simple timeout is robotic. Too early, you cut people off. Too late, you create awkward dead air.
We solved this by building endpointing approaches that can be used individually or combined:
- Rule-Based Endpointing: Custom delays based on message content patterns—different timeouts for messages ending with numbers, punctuation, or plain statements.
- Intelligent Endpointing: A machine learning-based prediction that considers conversation context, speech patterns, and timing to determine optimal wait times.
- Custom External Models: Integration with external endpointing services that can apply domain-specific logic.
- Regex Pattern Matching: Advanced rule systems that can match against assistant responses, user inputs, or both to trigger context-specific endpointing behavior.
The system automatically chooses the best method based on conversation context, with intelligent fallbacks when advanced methods aren't available. This single change reduced premature interruptions by 73% compared to a fixed timeout.
Problem #5: Coordination
The first four components turn messy audio into a clean, intelligent prediction. This final component is about how the entire system acts on that prediction and what happens when the prediction is wrong.
Our endpointing model is good, but it's not perfect. So we use Greedy Inference. When we think a user is done, we immediately send their utterance to the LLM to start generating a response. If we're wrong and they continue speaking, we instantly cancel that LLM request and start a new one with the complete, updated utterance. The user never hears the scrapped attempt.
But what if the user interrupts while the AI is already speaking? This triggers a system-wide interruption sequence that must complete in under 100ms:
- VAD detects the speech start and emits events.
- The LLM request is aborted.
- TTS generation stops immediately.
- Audio buffers are cleared to prevent glitchy playback.
- The system switches to listening mode to capture the new input.
The trickiest part is context reconstruction. Since LLMs generate faster than we can speak, we often have audio queued up. We use word-level timestamps from the TTS provider to reconstruct exactly which words the user actually heard before they interrupted, ensuring the conversation context remains perfectly synchronized with the user's experience.
These components, coordinated through an event-driven architecture, form the core of our streaming pipeline. Each one was born from solving a real-world failure.
What's Next
In Part 3, we'll dive into the production challenges that emerge when you deploy this system at scale: advanced features like voicemail detection and DTMF handling, performance optimization, and how we test and monitor a system that is fundamentally non-deterministic.






















































