
Vapi raises $50M Series B
Read More →How We Built Vapi's Voice AI Pipeline: Part 1

A few years back, most voice AI systems felt like talking to a robot reading from a script.
The pattern never changed- speak, wait through dead silence, then receive a robotic, pre‑recorded‑sounding response. Over and over again.
That's because the traditional voice AI process was a feature of a fundamentally broken architecture that the entire industry has been using for years.
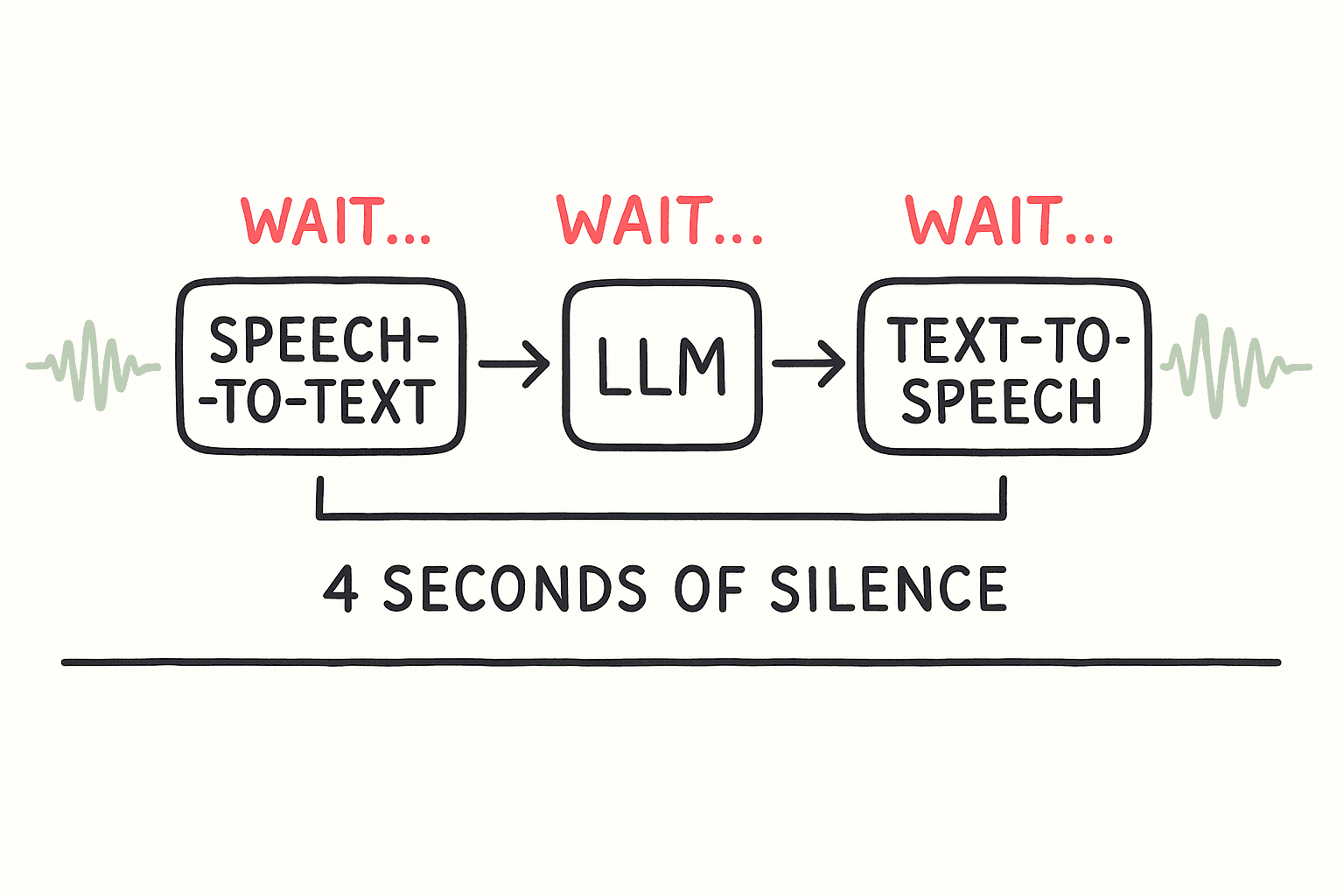
It’s a problem we call the Batch Processing Cascade, and it’s the single biggest reason most voice agents feel robotic.
This is the story of why we had to abandon that model and build our pipeline around a completely different philosophy.
The Flawed Foundation
The traditional approach to voice automation was intent-based.
You'd map out a rigid decision tree, and the system would listen for keywords ("billing," "support") to navigate it. It was reliable but brittle. Any deviation from the script broke the experience.
It was reliable but brittle. Any deviation from the script broke the experience.
Speech-to-Text (wait) → NLP (wait) → Text-to-Speech (wait)
The modern, LLM-based pipeline seems more flexible, but it introduces a new problem: latency. It's a simple, sequential chain
The standard approach follows three sequential steps:
Step 1: Speech-to-Text (STT)
- Wait for the user to finish speaking completely
- Send the entire audio chunk to a transcription service
- Wait for the full transcript to come back
Step 2: Large Language Model (LLM)
- Send the complete transcript to the LLM
- Wait for the model to generate a full response
- Return the entire text response
Step 3: Text-to-Speech (TTS)
- Send the complete text to a voice synthesis service
- Wait for the entire audio to be generated
- Play the full audio response to the user
This cascade of waiting creates over 4 seconds of dead air between turns. It treats conversation like a series of isolated transactions, not a continuous flow.
Real conversation is messy and overlapping. This architecture is fundamentally designed to fail at it.
Our Solution
We realized the only way to solve this was to stop thinking in batches and start thinking in streams.
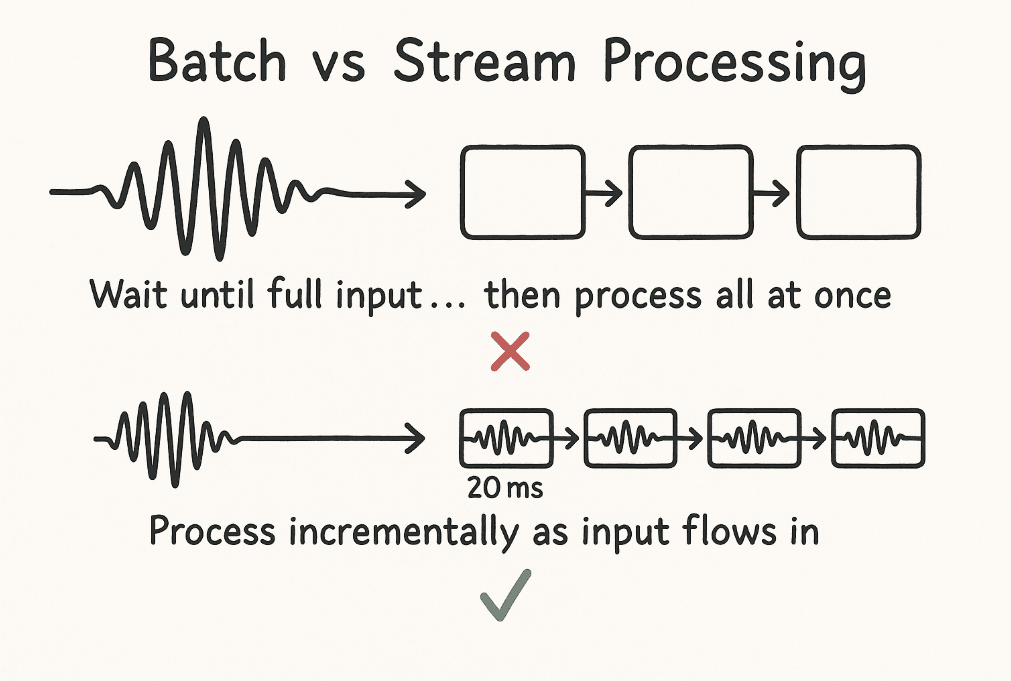
We had to process audio the same way humans do: continuously, in real-time, making decisions on partial information.
This meant re-architecting everything to handle audio in 20ms chunks instead of multi-second files.
A streaming architecture is more complex, but it’s the only way to solve conversational flow. Here’s how it works.
The Vapi Streaming Pipeline
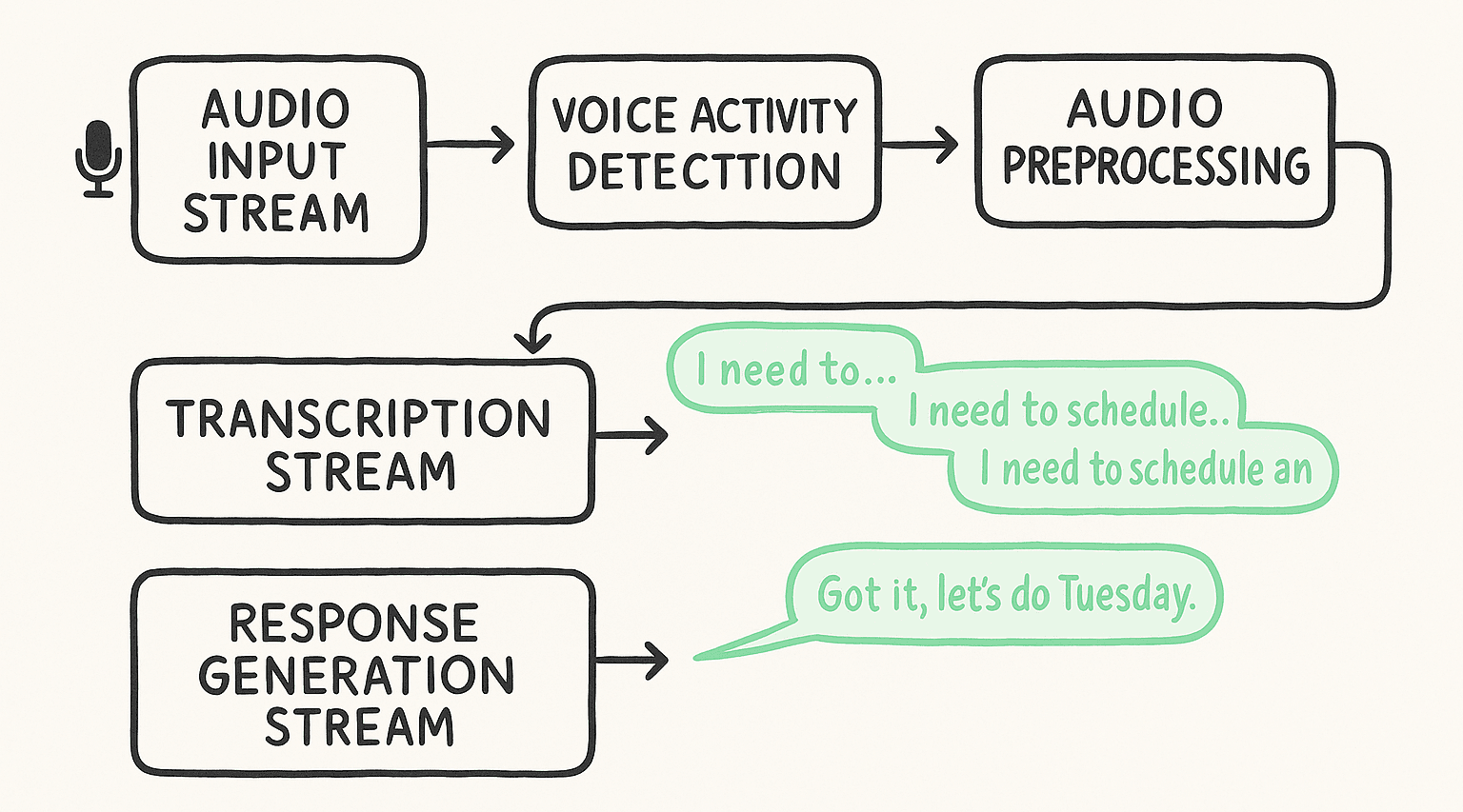
Our pipeline processes audio through three parallel streams that work together in real-time.
1. The Audio Input Stream
Instead of waiting for a complete audio file, the Input Stream processes audio in 20ms chunks as it arrives. It’s responsible for the first critical decisions::
- Voice Activity Detection: Is someone actually speaking or is this just background noise?
- Audio Preprocessing: Clean up the audio to improve transcription accuracy
- Real-time Buffering: Passing clean audio chunks to the next stage with minimal delay.
2. The Transcription Stream
We use streaming speech recognition that provides partial results as the user speaks.
This means we get transcripts like:
- "I need to..."
- "I need to schedule..."
- "I need to schedule an appointment..."
- "I need to schedule an appointment for Tuesday"
Each partial result gets fed into the next stage immediately, rather than waiting for the complete sentence.
3. The Response Generation Stream
The LLM starts working with partial information and generates responses incrementally.
Our endpointing model predicts when the user has likely finished their thought. At that moment, we send the complete utterance to the LLM.
If our model is wrong and the user continues speaking, we scrap that LLM request and start a new one with the updated transcript. This predict and scrap method is critical for responsiveness without generating nonsensical, premature responses.
Where Things Get Complex
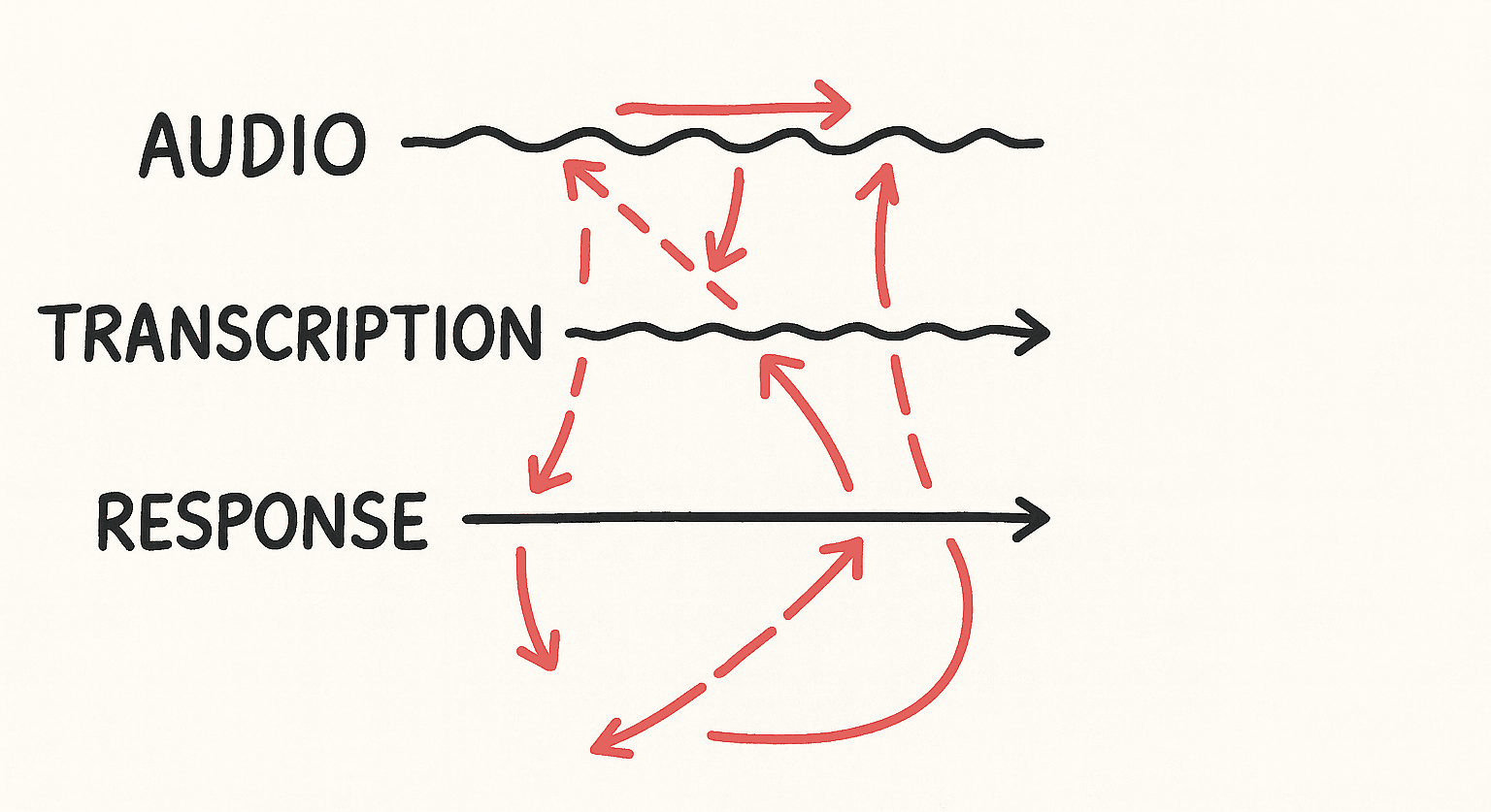
Having three parallel streams sounds good in theory. In practice, coordinating them is where most implementations fall apart.
Consider this seemingly simple scenario: a user starts to say "I need to schedule..." but then pauses mid-sentence to think.
What should the system do? Wait for more audio? Start generating a response based on the partial text? What if the user starts talking again just as the AI begins to respond?
We tried the obvious approaches first. Fixed timeouts, simple buffering, basic state machines.
They didn't work.
Making intelligent decisions with partial, noisy, real-world audio is where the real work begins. We quickly discovered that every component hid immense complexity:
- VAD: distinguishing a pause from background TV.
- Turn Detection: deciding when a partial transcript is confident enough.
- Interruptions: cutting off a response the moment the user jumps back in.
- Audio Handling: echo, cross-talk, bad cell networks.
The breakthrough came when we realized that coordination between streams is a conversation understanding problem. Each stream needs to be aware of what the others are doing and what it means for the conversation as a whole.
What's Next
This is Part 1 of our 3-part series on how we built Vapi's voice pipeline.
In Part 2, we’ll break down the specific components we had to build to make this work in production- from a VAD that can handle a crowded coffee shop to an endpointing model that knows when you're done speaking versus just thinking.
Stay tuned.
Follow us to get notified when Part 2 drops.























































