
Vapi raises $50M Series B
Read More →How We Achieved 99.99% Reliability At Vapi

At Vapi, we're obsessed with the quality of conversation. But the most human-like AI is useless if the line drops.
A while ago, we were at a respectable ~99.9% uptime. That's about 8 hours of downtime a year. That was still a lot so we set an ambitious goal: 99.99% uptime which is less than an hour of downtime per year.
But getting from 99.9% to 99.99% is a different game. We didn't have to do 1 thing 100x better but 100 things 1x better.

It required a top-to-bottom re-architecture.
That effort was led by our core team: Tejas, Sagar, and Bryant.
This is how they did it.
The Core
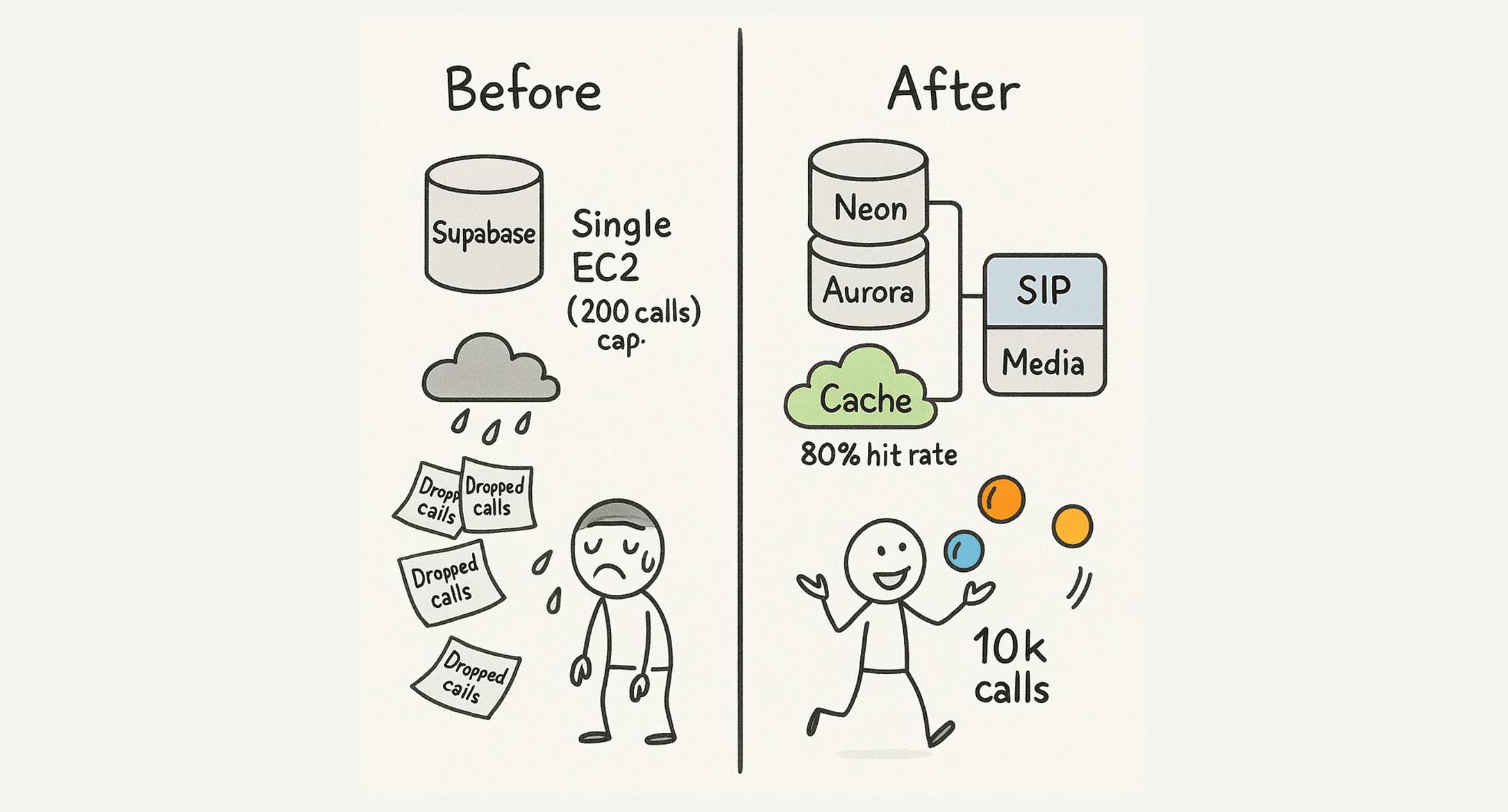
Our journey started with the database. Our initial setup with Supabase was great for getting started, but it became a single point of failure at scale.
We migrated our primary database to Neon for better stability. But a better database wasn't enough. We needed redundancy. We engineered a fallback system to AWS Aurora. If Neon has an issue, we fail over with minimal disruption.
We also added guardrails like aggressive statement timeouts to kill rogue queries, partitioning massive tables to keep them fast, and a caching layer in front of the DB.
That cache now serves 80% of eligible requests, meaning 4 out of every 5 database requests that have the cache in front of them are served from a low-latency cache, making the entire platform faster and more resilient.
On the telephony side, our SIP was running on a single EC2 instance that capped out at around 200 concurrent calls.
We moved it to auto-scaling groups (ASGs) for each component.
This eliminated the bottleneck and let us handle sudden traffic spikes without dropping calls.
We thought we were on our way. We were wrong.
The "Fallbacks Everywhere" Philosophy
Our own infrastructure was becoming more stable, but our agents still felt unreliable.
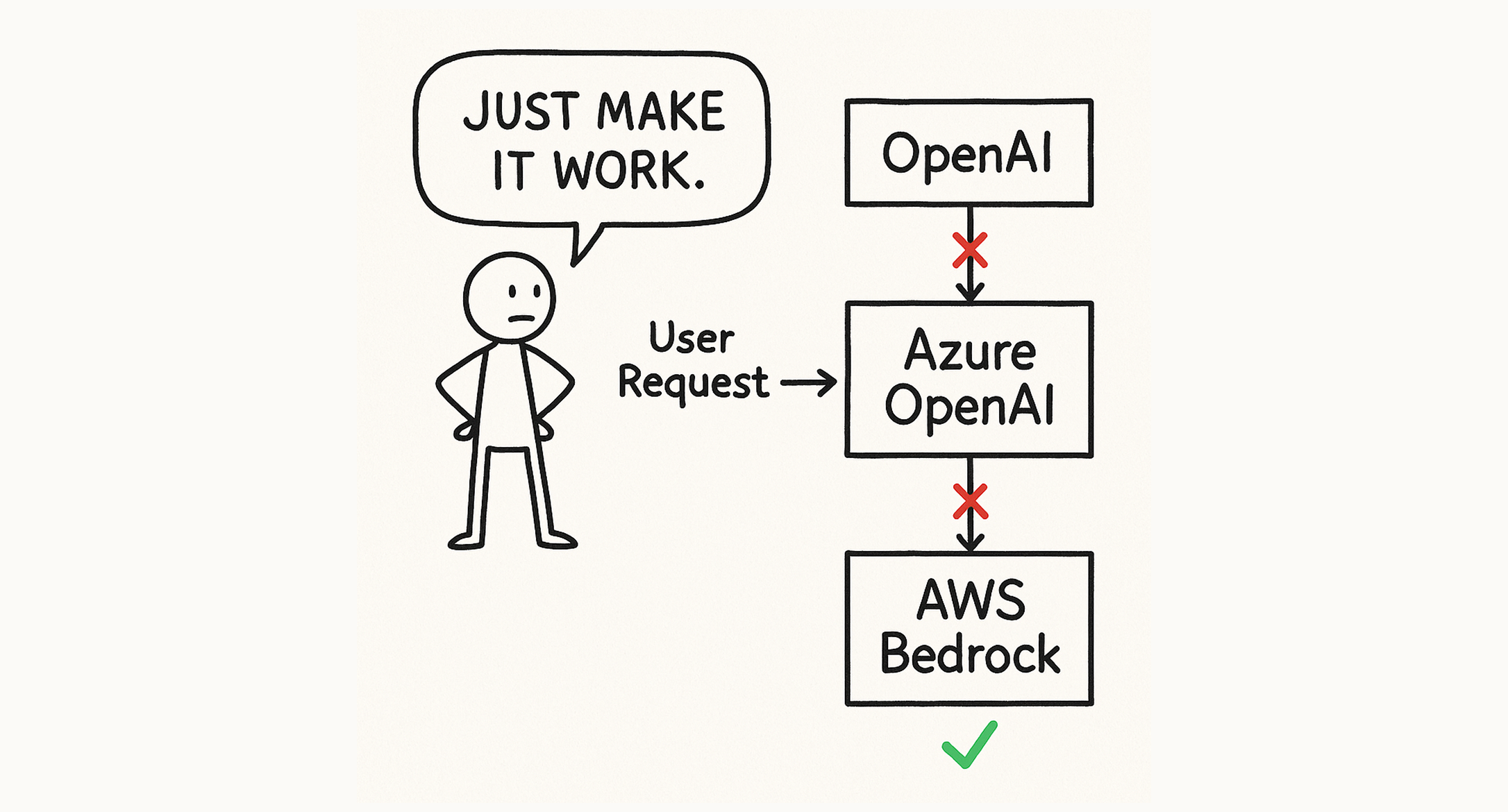
The problem was with our dependencies. We treat every external provider as a potential point of failure.
For AI models, we fall back between a chain of models. If OpenAI fails, we instantly retry on Azure OpenAI. If that is down, we jump to AWS Bedrock. The switch happens inside the request lifecycle, so a provider outage never becomes a Vapi outage.
We carry this "fallbacks everywhere" philosophy to other critical systems as well. Our DTMF (touch-tone) transmission uses a dual-strategy approach: we try the provider's native API first, but if that fails, we automatically fall back to sending the tones as audio signals.
This gives us a 98%+ overall success rate for navigating automated phone systems, even when individual methods fail.
Architecting for Resilience and Scale
With external dependencies handled, we had to face the next biggest threat to uptime: our own deployments.
A single bad deploy can wipe out hard-earned reliability. Deploying directly to production is playing with fire.
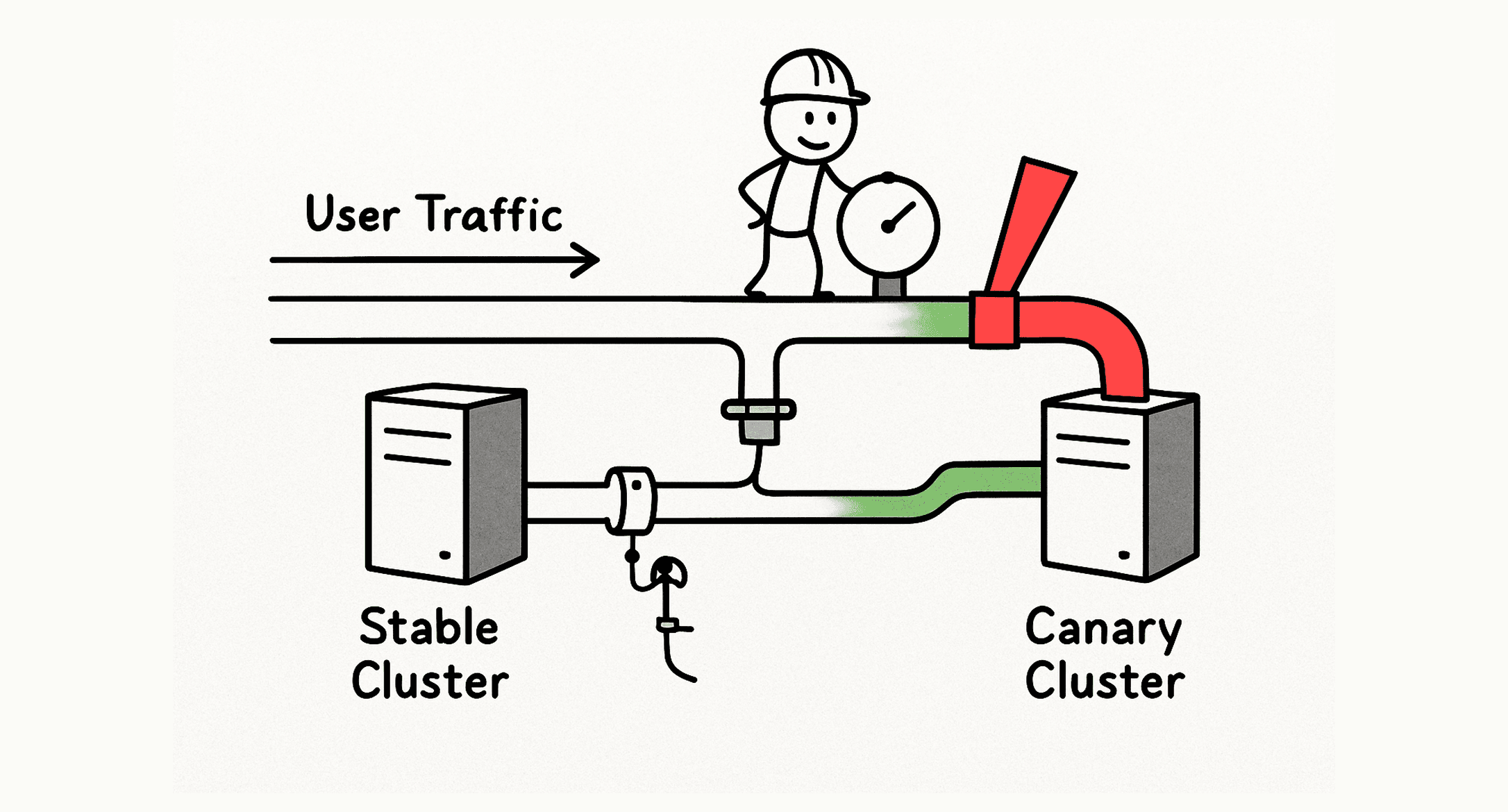
To solve this, we moved from a single production cluster to a multi-cluster architecture with a dedicated Canary Manager service.
When we release a new version:
- It's deployed to a "canary" cluster with no traffic.
- Our Canary Manager slowly "drips" traffic to it, starting with as little as 5% of requests.
- It monitors error rates and API health. If anything looks wrong, it automatically rolls back.
- If the new code is stable, it gradually increases the traffic and becomes the new production cluster.
This automated, safety-first approach to deployments was a massive step forward.
Handling Spikes with Lambda "Burst Workers"
Voice traffic is incredibly spiky. A customer can launch a call campaign and go from 10 to 10,000 concurrent calls in minutes. Our Kubernetes cluster can autoscale, but VMs take time to spin up.
To bridge that gap, we built Lambda burst workers. When our worker scaler detects a backlog, AWS Lambda functions fire instantly to handle overflow.
The challenge was that these Lambda functions exist outside our secure private network.
We solved it with a custom QUIC-based proxy that creates a secure, low-latency tunnel from the Lambda environment into our Kubernetes cluster.
This lets burst workers talk to Redis and databases like they’re local, so even massive spikes pass unnoticed to the end user.
Guaranteeing Completion With Temporal
Our infrastructure was resilient. Our deployments were safe. But what happens if a server crashes halfway through provisioning a phone number?
These business-logic failures are just as damaging as infrastructure outages.
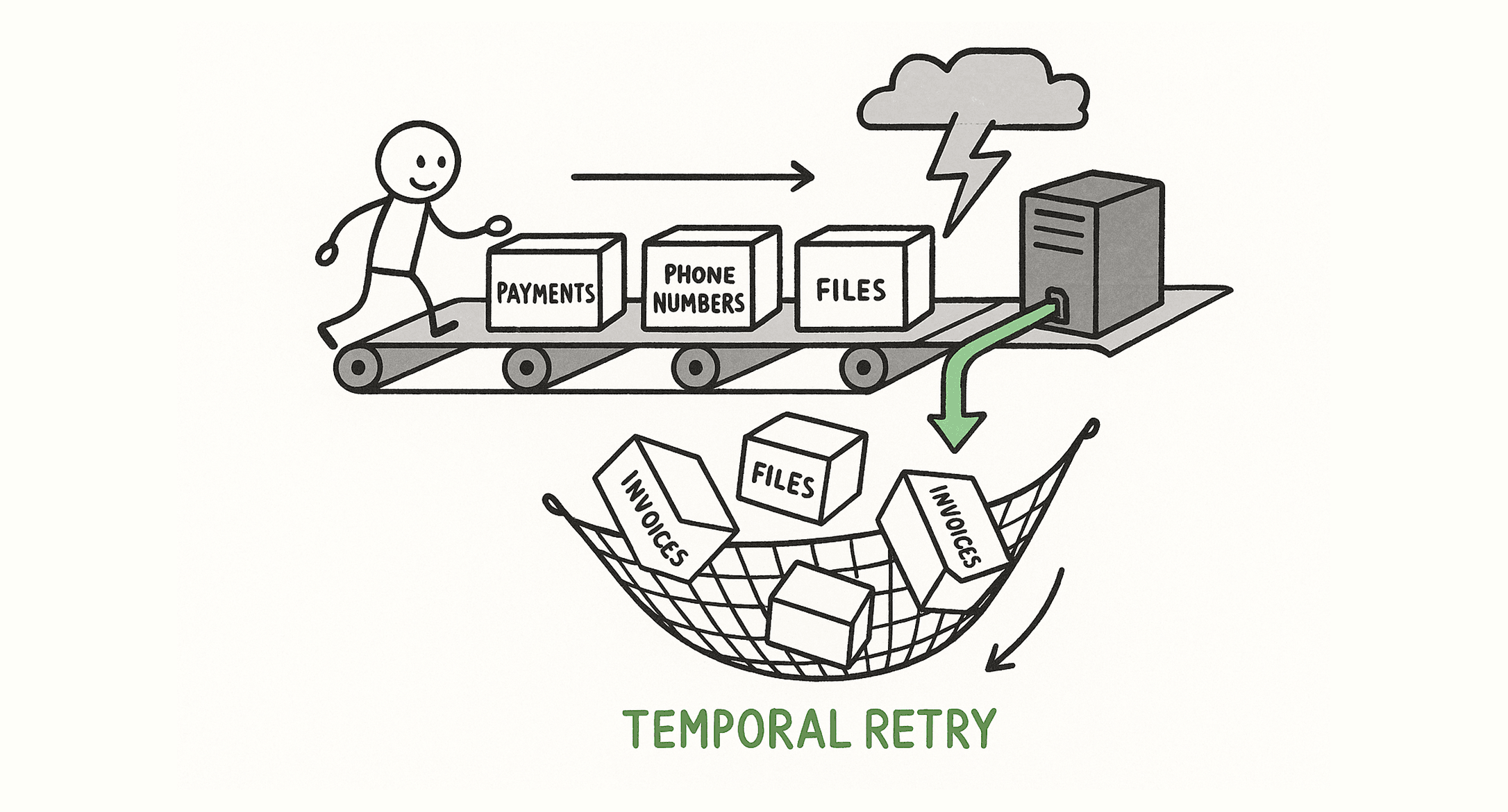
To solve this, we integrated Temporal, a durable execution platform.
It allows us to write "workflows" that are guaranteed to run to completion, with state automatically saved and retried across failures.
We wrapped all of our most critical business logic in Temporal workflows:
- Stripe payment handling
- Phone number purchasing
- User creation
This ensures that our core business operations are just as fault-tolerant as our infrastructure.
Additional Reliability Patterns
Beyond these major pillars, we've implemented several other critical reliability patterns:
- Process Isolation: Every call runs in its own isolated virtual machine with dedicated compute resources. This prevents "noisy neighbor" issues where one problematic call could impact others.
- Circuit Breakers: We use circuit breaker patterns throughout our voice pipeline to prevent cascading failures. When a component starts failing, the circuit breaker stops sending requests to it, allowing it to recover.
- Comprehensive Monitoring: Our monitoring evolved from simple uptime checks to sophisticated error rate analysis, performance tracking across multiple AI providers, and real-time alerting that can trigger automatic remediation.
The Results
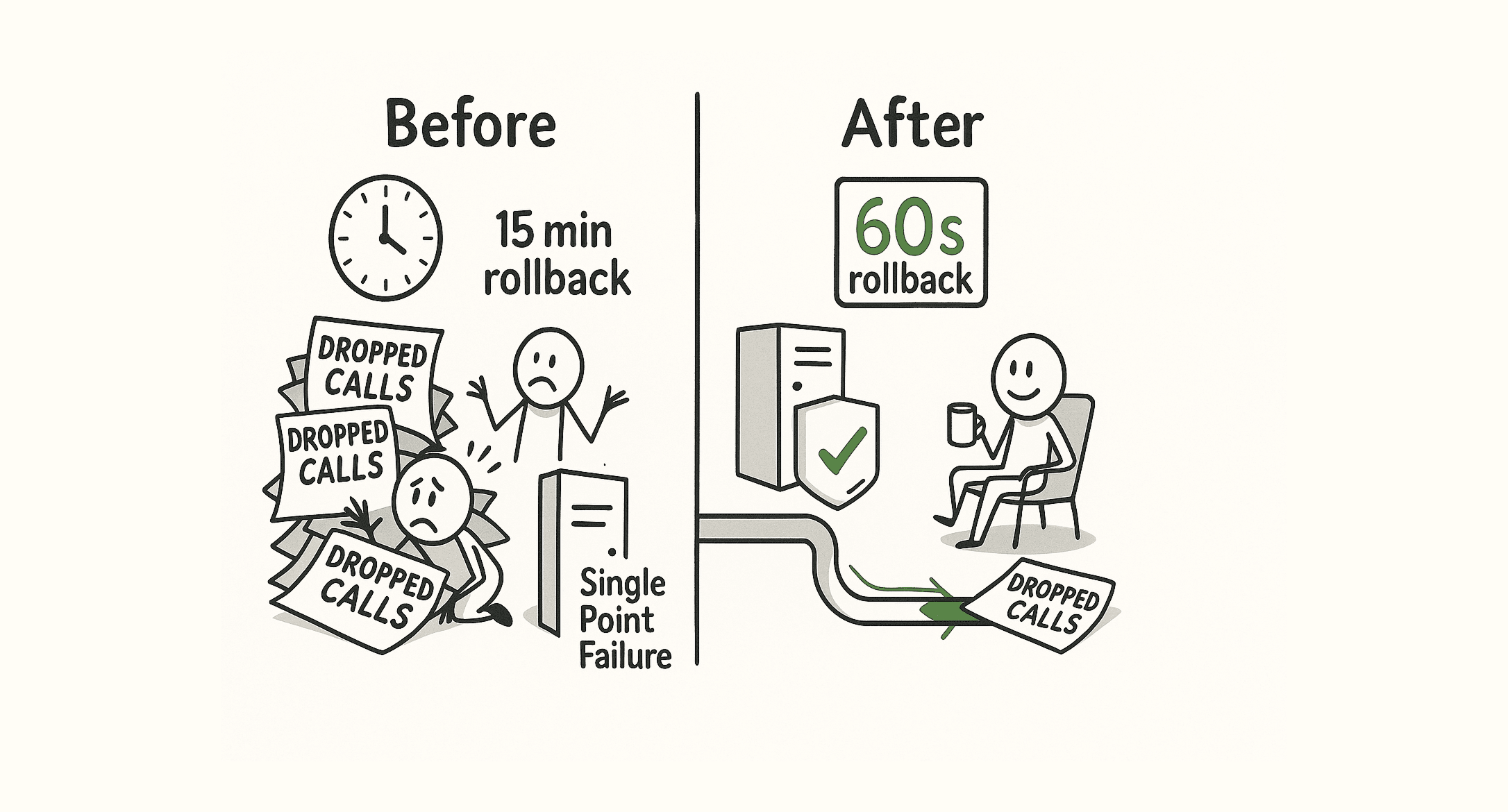
The transformation was measurable:
Before (99.9% era):
- Frequent dropped calls, especially during traffic spikes.
- Single points of failure in database and SIP infrastructure
- Manual rollback procedures taking 15+ minutes
- A provider outage meant a Vapi outage.
After (99.99% era):
- A 97% reduction in dropped calls.
- Multi-region database fallbacks with <5 second failover
- Automated canary rollbacks in under 60 seconds
- Provider outages are handled by automatic failover chains.
Reaching 99.99% was a mix of dozens of architectural changes, new systems, and safety mechanisms. It’s the foundation developers need to build applications they can actually trust.
The most sophisticated AI means nothing if the call drops.
If you're an engineer who reads a post like this and gets excited, you're the type of person we're looking for.
We're hiring. See our open roles and the problems you could be solving here.












































