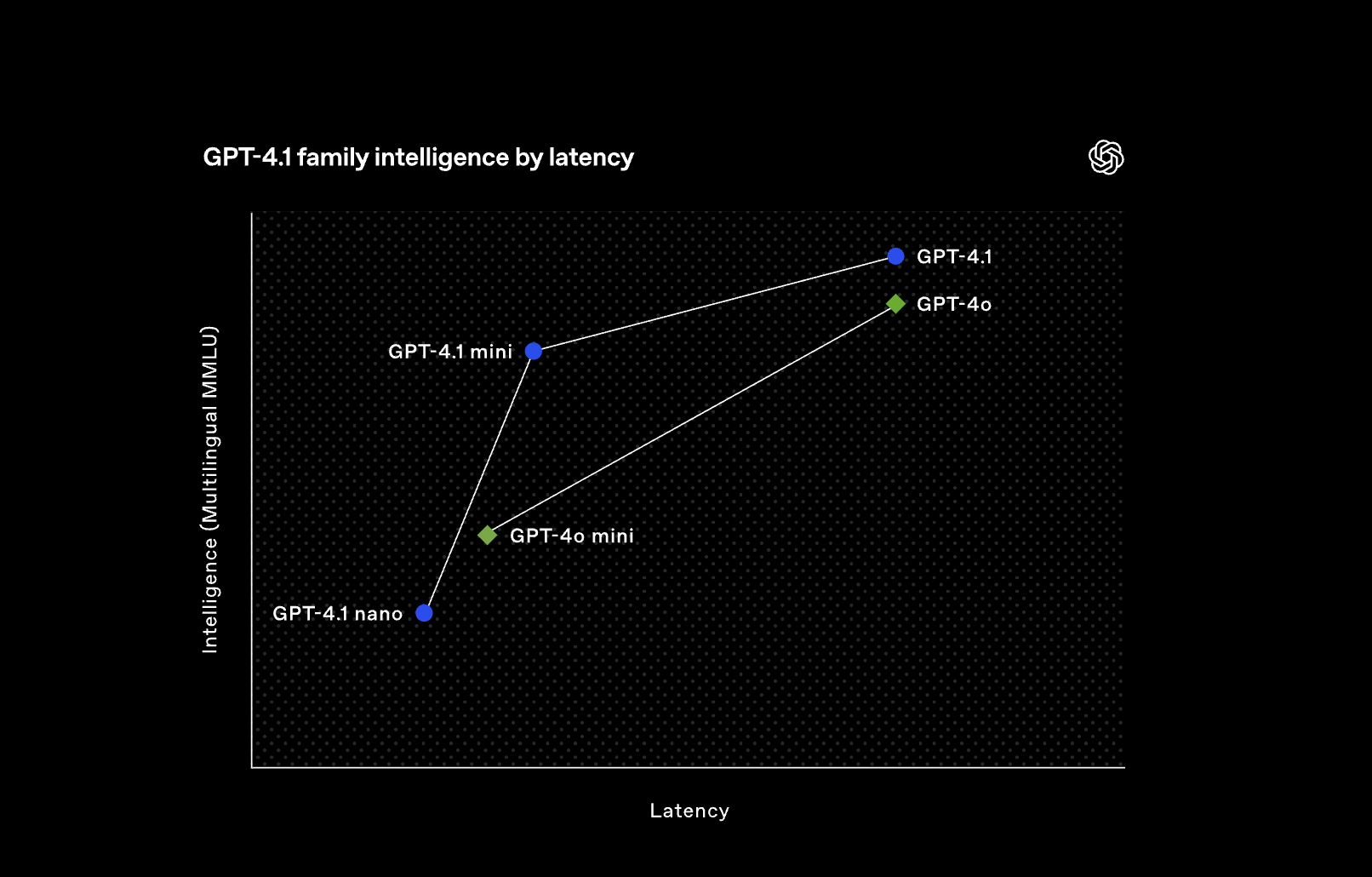
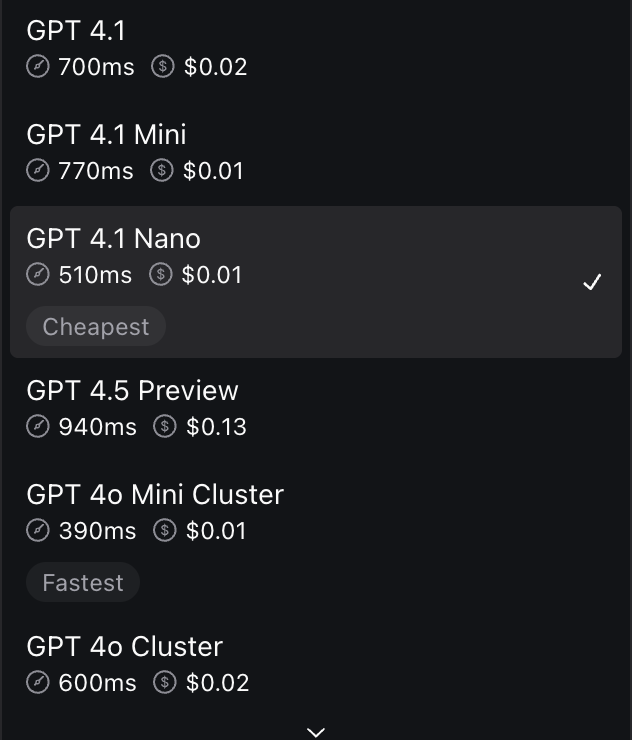
i have an issue with the open AI models in vapi.
When gpt 4.1 nano appeared in the llm options in vapi assistans, it had an 250 latency and it was the fastest one. However in the past severl weeks it appears as 510 latency that is well slower that the previous 4o mini. Do you know what should be done to restore it to its original 250 latency?