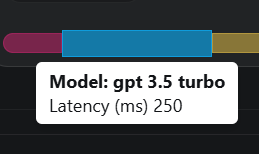
The estimated latency for GPT-3.5-turbo indicates 250ms; even though it's an estimation, this latency is extremely low compared to the actual latency, which is around 600ms. How was this 250ms estimation calculated?
Vapi helps developers build, test, and deploy voice agents at scale. We enable everything in between the raw models and production, including telephony, test suites, and real-time analytics.